目录
简要
最近打算换工作,面试了差不多十家公司的3到5年的Android开发职位。现在准备对这次面试做一些知识经验总结。总体来说,一个合格的Android开发者,应该具有Java/Kotlin,Android,Java虚拟机,设计模式,计算机网络,数据结构+算法,数据库,计算机操作系统等方面的知识。
Java
Java是Android开发的基础,问到Java知识时,会考察一些基本的知识,比如:异常,泛型,集合框架,线程等。
- ==:如果是基本数据类型,表示两个变量数值是否相等;如果是对象,表示两个对象内存地址是否相同。
- equals:在Object的equals方法实现中,用的是==,所以默认情况下equals方法和==表达的意思是相同的。另外,有些类会重写equals方法,如String、Integer、Double类等,在String类中equals方法表示两个对象的内容是否相等,在Integer类中equals方法表示两个对象数值是否相等。下面为Object,String和Integer类的equals方法:
//Object类
public boolean equals(Object obj) {
return (this == obj);
}
//String类
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String) anObject;
int n = length();
if (n == anotherString.length()) {
int i = 0;
while (n-- != 0) {
if (charAt(i) != anotherString.charAt(i))
return false;
i++;
}
return true;
}
}
return false;
}
//Integer
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}
两个值相等的 Integer 对象,== 比较,判断是否相等?
答案:结果false,因为“==”比较对象,是判断两个对象内存地址是否相同;但用equals方法,结果true,因为 Integer 的 equals方法是判断两个对象的数值是否相等。
2. “equals”和”hashcode”有什么关系?
- 在一个应用程序执行期间,如果一个对象的equals方法做比较所用到的信息没有被修改的话,那么,对该对象调用hashCode方法多次,它必须始终如一地返回同一个整数。在同一个应用程序的多次执行过程中,这个整数可以不同,即这个应用程序这次执行返回的整数与下一次执行返回的整数可以不一致。
- 如果两个对象根据equals(Object)方法是相等的,那么调用这两个对象中任一个对象的hashCode方法必须产生同样的整数结果。
- 如果两个对象根据equals(Object)方法是不相等的,那么调用这两个对象中任一个对象的hashCode方法,不要求必须产生不同的整数结果。然而,程序员应该意识到这样的事实,对于不相等的对象产生截然不同的整数结果,有可能提高散列表(hash table)的性能。
3. “wait”和”sleep”方法的区别是什么?
- wait是Object类的方法,会释放锁。
- sleep是Thread类的方法,不会释放锁。
4. String str1 = new String(“abc”)和String str2 = “abc”有什么区别?执行代码String str2 = “abc” ,在Java 虚拟机中内存是如何分配的?
String str1 = new String("abc")创建了两个对象,一个是”abc”对象,一个是new String(“abc”)产生的对象。String str2 = "abc"创建了一个对象。
下面String类的构造方法说明了为什么new String(“abc”)会创建两个对象:
public String(String original) {
...
}
在Java的main 方法中定义String str2 = "abc" ,Java 虚拟机中的内存是怎样分配的?。
- Java运行时会维护一个String Pool,也叫“字符串缓存区”。 String Pool 用来保存运行时产生的各种字符串,并且池中的字符串内容不重复。
- String Pool的存在主要为了同样的字符串内容只保存一份,同样内容的字符串创建新对象时,只需要创建一个新的引用即可。
- jdk1.7 之前 hotspot JVM中常量池位于方法区,而jdk1.7之后,常量池从方法区移除,移到了堆中。
下面代码输出结果:
String str1 = "abc";
String str2 = "abc";
String str3 = new String("abc");
str1==str2 结果为true
str1==str3 结果为false
5. 如何用String str1 = “abc”,String str2 = “def”,String str3 = “ghi”得到”abcdefghi”字符串。
主要考察字符串操作,如果用str = str1 + str2 + str3必然不是一个好的方式,因为在常量池中会产生不必要的字符串对象,如”abcdef”。以下为正确的操作,只会产生一个对象”abcdefghi”:
StringBuilder sb = new StringBuilder();
sb.append(str1);
sb.append(str2);
sb.append(str3);
str = sb.toString();
有时候还会问到String,StringBuilder和StringBuffer类的区别。
6. switch语句可以作用在哪些类型上?
switch只接受整型表达式,因为char , byte , short ,Enum可以转换为整型表达式,所以switch也接受这些类型。在Java7中支持了String类型,其实也是通过String的hashCode来实现的,还是整型。
7. 说说对异常的理解?
异常分为Exception和Error,Exception和Error类都继承自Throwable类。
- Exception:表示程序可以处理的异常,可以捕获并且可恢复。遇到这类异常,应该尽可能处理异常,使程序恢复运行,而不应该随意终止异常。
- Error:一般指虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢出等。这于这类错误,Java编译器不去检查也会导致应用程序中断,仅靠程序本身无法恢复和预防,遇到这样的错误,建议程序终止。
Exception分为运行时异常和受检查的异常:
- 运行时异常:如空指针,参数错误等。
- 受检查异常:这类异常如果没有try/catch语句也没有throws抛出,编译不通过。
8. 说说对泛型的理解?泛型中通配符extends和super分别表示什么?泛型擦除?什么情况下不会出现泛型擦除?
Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许在编译时检测到非法的类型。泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数。泛型主要是防止类型转换错误。
- < ? extends T>限定参数类型的上界:参数类型必须是T或T的子类型。
- < ? super T> 限定参数类型的下界:参数类型必须是T或T的超类型。
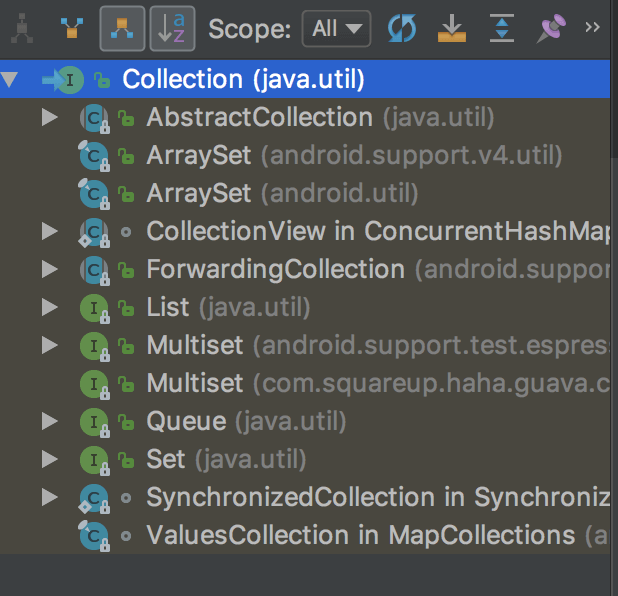
9. 说说实现了Collection接口的类都有哪些?
List , Queue , Set , ArraySet集合都实现了Collection接口。注意没有Map集合。
10. ArrayList,LinkedList、Vector和CopyOnWriteArrayList的的区别?
- ArrayList:使用数组存储数据元素,线程不安全;默认大小是10,扩容时增长原来大小的50%。如果构造函数不传递
initialCapacity, 创建了一个空数组。 - LinkedList:使用链表存储数据元素,线程不安全。
- Vector:使用数组存储数据元素;默认大小是10,扩容时增长原来大小的一倍。线程安全。
- CopyOnWriteArrayList:在每次修改时,都会创建并重新发布一个新的容器副本,从而实现可变性。“写入时复制“容器的迭代器保留一个指向底层数组的引用,这个数组当前位于迭代的起始位置,由于它不会被修改,因此在对其进行同时只需要确保数组内容的可见性。线程安全。
- ArrayDeque:使用数组存储数据元素,线程不安全;默认大小是16,扩容时保证数组长度总是2的n次方;不提供根据索引访问数据,使用2个变量来记录队列的头部和尾部。
add元素在尾部,poll元素在头部。
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity();
}
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}
与运算符用符号“&”表示:两个操作数中位都为1,结果才为1,否则结果为0。
16&15 = 0;
13&15 = 13;
- LinkedHashMap:HashMap+双向链表,有序的HashMap,线程不安全。它的构造函数有一个参数是
accessOrder,这个参数表示的意思是:false 基于插入顺序;true 基于访问顺序 。默认false,在LruCache中参数accessOrder为true。
11. HashMap和ConcurrentHashMap的实现原理?HashMap与ConcurrentHashMap和SynchronizedHashMap的区别?
- HashMap1.7和1.8 版本的区别
- CAS:Java 并发编程实战 ,P263
HashTable中的线程安全:
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
HashtableEntry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
HashtableEntry<K,V> entry = (HashtableEntry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
SynchronizedMap的线程安全:
private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
ConcurrentHashMap 1.7:并不是将每个方法都在同一个锁上同步并使得每次只能有一个线程访问容器,而是使用一种粒度更细的加锁机制来实现更大程度的共享,这种机制称为分段锁。在这种机制中,任意数量的读取线程可以并发访问Map。执行读取操作的线程和执行写入操作的线程可以并发地访问Map,并且一定数量的写入线程可以并发的修改Map。线程安全。
在ConcurrentHashMap的实现中使用了一个包含16个锁的数组,每个锁保护所有散列桶的1/16,其中第N个散列桶由第(N mod 16)个锁来保护。
12. ThreadLocal 的原理?子线程之间如何通信?
ThreadLocal:
线程范围内的数据共享,针对某一个线程存储数据。
每一个线程
Thread都有一个ThreadLocalMap(Thread#threadlocals),在调用ThreadLocal#set方法时,如果当前线程的threadlocals变量为空,就会创建一个 ThreadLocalMap 对象给它赋值,不为空就直接调用ThreadLocalMap 的 set 方法。ThreadLocalMap 以数组的形式存储数据,数组初始大小为16,创建一个ThreadLocalMap 对象需要一个ThreadLocal对象和存储的数据对象。ThreadLocal 对象就是当前对象,根据ThreadLocal对象的hashCode计算出数组下标。
当前大小大于或等于(阀值大小-阀值大小/4)时,就会扩容,扩大为原来的2倍。
子线程之间如何通信:
利用Android的消息机制,可以使用HandlerThread。
使用synchronized,cas或lock同步机制通信。
13. 说说线程的5中状态?如何设置线程的优先级?
5中线程状态:
- 新建:创建后尚未启动的线程处于这种状态。
- 运行:Runnable包括了操作系统线程中的running和ready,也就是处于此状态的线程有可能正在执行,也有可能正在等待CPU为它分配时间。
- 无限期等待:处于这种状态的线程不会被分配CPU执行时间,它们要待被其它线程显示的唤醒。以下会让线程陷入无限期的等待状态:没有设置Timeout参数的Object.wait()方法;没有设置Timeout参数的Thread.join()方法;LockSupport.park()方法。
- 限期等待:处于这种状态的线程也不会被分配CPU执行时间,不过无须等待被其它线程显示的唤醒,在一定时之后它们会由操作系统自动唤醒。以下会让线程进入限期等待状态:Thread.sleep()方法;设置了Timeout参数的 Object.wait()方法;设置了Timeout参数的Thread.join()方法;LockSupport.parktNanos()方法;LockSupport.parkUntil()方法。
- 阻塞:线程被阻塞了,“阻塞状态“与“等待状态“的区别是:“阻塞状态“在等待获取一个排它锁,这个事件将在另一个线程放弃这个锁的时候发生,而“等待状态“则是等待一段时间,或者唤醒动作的发生。在程序等待进入同步区域的时间,线程将进入这种状态。
- 结束:已被终止线程的状态,线程已经结束执行。
设置线程的优先级:
/**
* Changes the priority of this thread.
* <p>
* First the <code>checkAccess</code> method of this thread is called
* with no arguments. This may result in throwing a
* <code>SecurityException</code>.
* <p>
* Otherwise, the priority of this thread is set to the smaller of
* the specified <code>newPriority</code> and the maximum permitted
* priority of the thread's thread group.
*
* @param newPriority priority to set this thread to
* @exception IllegalArgumentException If the priority is not in the
* range <code>MIN_PRIORITY</code> to
* <code>MAX_PRIORITY</code>.
* @exception SecurityException if the current thread cannot modify
* this thread.
* @see #getPriority
* @see #checkAccess()
* @see #getThreadGroup()
* @see #MAX_PRIORITY
* @see #MIN_PRIORITY
* @see ThreadGroup#getMaxPriority()
*/
public final void setPriority(int newPriority) {
ThreadGroup g;
checkAccess();
if (newPriority > MAX_PRIORITY || newPriority < MIN_PRIORITY) {
// Android-changed: Improve exception message when the new priority
// is out of bounds.
throw new IllegalArgumentException("Priority out of range: " + newPriority);
}
if((g = getThreadGroup()) != null) {
if (newPriority > g.getMaxPriority()) {
newPriority = g.getMaxPriority();
}
synchronized(this) {
this.priority = newPriority;
if (isAlive()) {
nativeSetPriority(newPriority);
}
}
}
}
14. 说说 Thread 中的start, sleep, interrupt, interrupted, isInterrupted, yield, join 方法各表示什么意思?
Thread#start 启动一个线程,不可重复调用。
Java里一个线程调用了Thread.interrupt()到底意味着什么?
Thread # interrupt 方法:
- 如果线程处于被阻塞状态(例如处于sleep, wait, join 等状态),那么线程将立即退出被阻塞状态,并抛出一个InterruptedException异常。
- 如果线程处于正常活动状态,那么会将该线程的中断标志设置为 true。被设置中断的线程将继续正常运行,不受影响。
Thread # interrupted 方法:
- 清除标志位是为了下次继续检测标志位。
Thread # isInterrupted 方法:
- 仅仅是检测标志位。
Thread # yield
作用:暂停当前正在执行的线程对象,并执行其他线程。
yield() 让当前运行线程回到可运行状态,以允许具有相同优先级的其他线程获得运行机会。因此,使用yield()的目的是让相同优先级的线程之间能适当的轮转执行。但是,实际中无法保证yield()达到让步目的,因为让步的线程还有可能被线程调度程序再次选中。
Thread # join
作用:使当前线程交换执行权,等待另一个线程执行完毕后,继续执行。
15. 用户线程和守护线程的区别?
用户线程即运行在前台的线程,而守护线程是运行在后台的线程。守护线程作用是为其它前台线程的运行提供便利服务,而且仅在普通、非守护线程仍然运行时才需要,比如垃圾回收线程就是一个守护线程。当VM检测仅剩一个守护线程,而用户线程都已经退出运行时,VM就会退出,因为如果没有了守护者,也就没有继续运行程序的必要了。如果 有非守护线程仍然活着,VM 就不会退出。
16. volatile,synchronized关键字的含义,volatile用法?
volatile:
- 保证此变量对所有的线程的可见性,这里可见性指当一个线程修改了这个变量的值,新值对于其它线程来说可以立即得知。保证新值能立即同步到主内存。
- 禁止指令重排(不会将该变量上的操作与其它内存操作一起重排序)。
原理:lock指令,形成内存屏障。
不执行互斥访问,但可以保证任何一个线程在读取的时候都将看到最近写入的值。对于一个volatile变量的写操作先发生于后面对这个变量的读操作。
volatile用法:
- 对变量的写入操作不依赖变量的当前值,或者你能确保只有单个线程更新变量的值。
- 该变量不会与其它变量一起纳入不变条件中。
- 在访问变量时不要加锁。
一种典型用法:检查某个状态标记以判断是否退出循环。
synchronized:
- synchronized关键字经过编译之后,会在同步块的前后分别形成monitorenter和monitorexit这个两个字节指令。这两个字节码都需要一个reference类型的参数来指明要锁定和解锁的对象。
同步指令:Java虚拟机可以支持方法级的同步和方法内部一段指令序列的同步,这两种同步结构都是使用管程 (Monitor)来支持的。
方法级的同步是隐式的,即无须通过字节码指令来控制,它实现在方法调用和返回操作之中。虚拟机可以从方法常量的方法表结构中的ACC_SYNCHRONIZED 访问标志得知一个方法是否声明为同步方法。当方法调用时,调用指令将会检查方法的ACC_SYNCHRONIZED 访问标志是否被设置,如果被设置了,执行线程就要要求先成功持有管理,然后才执行方法,最后当方法完成(无论是正常完成还是非正常完成)时释放管程。在方法执行期间,执行线程持有了管程,其它线程都无法再获取到同一个管程。如果一个同步方法执行期间抛出了异常,并且在方法内部无法处理此异常,那么这个同步方法所持有的管程将在异常抛到同步方法之外时自动释放。
synchronized 是内置锁,内置锁是可重入的锁。
- 内置锁:同步代码块。
- 重入锁:如果某个线程试图获得一个已经由它自己持有的锁,那么这个请求就会成功。
内存间交互操作:lock, unlock, read, load, use, assign, store, write
Synchronized(悲观锁) 和 CAS(乐观锁):
ynchronized 在 jdk 1.6 之后做了哪些优化?
17. synchronized作用在静态方法上和非静态方法上的区别?
synchronized作用在静态方法上锁住的是类对象,synchronized作用在非静态方法上锁住的是类实例对象。
18.使用synchronized还是ReentrantLock?
在一些内置锁无法满足需求的情况下,ReentrantLock可以作为一种高级工具。当需要一些高级功能时才应使用ReentrantLock,这些功能包括:可定时的、可轮询的与中断的锁获取操作,公平队列,以及非块结构的锁。否则,还是应该优先使用synchronized。
- 等待可中断:是指当持有锁的线程长期不释放锁的时候,正在等待的线程可以选择放弃等待,改为处理其他事情,可中断特性对处理执行时间非常长的同步块很有帮助。
- 公平锁:是指多个线程在等待同一个锁时,必须按照申请锁的时间顺序来依次获得锁;而非公平锁则不保证这一点,在锁被释放时,任何一个等待锁的线程都有机会获得锁。synchronized 中的锁是非公平的,ReentrantLock 默认情况下也是非公平的,但可以通过带布尔值的构造函数要求使用公平锁。
- 锁绑定多个条件是指:
在Java 5.0中,内置锁与ReentrantLock相比还有另一个有点:在线程转储中能给出在哪些调用帧中获得了哪些锁,并能够检测和识别发生死锁的线程。JVM并不知道哪些线程持有ReentrantLock,因此在调试使用ReentrantLock的线程时,将起不到帮助作用。Java 6.0解决了上诉问题。
读写锁(ReadWriteLock):一个资源可以被多个读操作访问,或者被一个写操作访问,但两者不能同时进行。
ReentrantLock在性能上似乎优于内置锁,其中在Java 6 中略有胜出,而在Java 5中远远胜出。
19. 说说JDK的提供线程池以及使用线程池的优势?
- 重用线程池中的线程,避免因为线程的创建和销毁所带来的性能开销。
- 能有效控制线程池中的最大并发数,避免大量的线程之间因互相抢占资源而导致阻塞现象。
- 能够对线程进行简单的管理,并提供定时执行以及指定间隔循环执行等功能。
20. newFixedThreadPool,newCachedThreadPool,newScheduledThreadPool,newSingleThreadExecutor的区别和使用场景?
- newFixedThreadPool:线程数量固定的线程池,当线程处于空闲时,它们并不会回收,除非线程池被关闭了。当所有的线程处于活动状态时,新任务都会处于等待状态,直到线程空闲出来。只有核心线程,没有非核心线程,最大线程量为核心线程数量,线程闲置时没有超时时长,使用的队列是LinkedBlockingQueue(无界队列)。 适用于任务量比较固定但耗时长的任务。
- newCachedThreadPool:线程数量不定的线程,最大线程数量为Integer.MAX_VALUE。当线程池中的线程都处于活动状态时,线程池会创建新的线程来处理新任务,否则就会利用空闲的线程来处理新任务。线程池中的线程都有超时机制,这个超时时长为60秒,超过线程就会被回收。 没有核心线程,只有非核心线程,最大线程量为Integer.MAX_VALUE,线程闲置时超时时长为60秒,使用的队列是SynchronoseQueue(没有存储功能,put 和 take 会一直阻塞,直到有另一个线程已经准备好参与到交付过程中。仅当有足够多的消费者,并且总是有一个消费者准备好获取交付的工作时,才适合使用同步队列。)。适用于大量耗时少的任务。
- newScheduledThreadPool:核心线程数量固定,非核心线程数量没有限制,并且非核心线程闲置时就会被回收。有核心线程,也有非核心线程,最大线程量为Integer.MAX_VALUE,线程闲置时超时时长为0秒,使用的队列是DelayWorkQueue。适用于执行定时任务和具体固定周期的重复任务。
- newSingleThreadExecutor:只有一个核心线程,确保所有的任务都在同一个线程中按顺序执行。有核心线程,没有非核心线程,最大线程量为1,线程闲置时没有超时时长,使用的队列是LinkedBlockingQueue(无界队列)。适用于多个任务顺序执行。
创建线程池ThreadPoolExecutor:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
- corePoolSize:核心线程。
- maximumPoolSize:最大线程数。
- keepAliveTime:线程闲置时的存活时间。
- unit:存活时间的时间单位。
- workQueue:存储任务的队列。
- threadFactory:线程工厂。
- handler:饱和策略。AbortPolicy (中止策略,默认方式,该策略会抛出未检查异常 RejectedExecutionException), CallerRunsPolicy(调用着运行策略实现了一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用着,从而降低新任务的流量) , DiscardPolicy(当新提交的任务无法保存到队列中等待执行时,抛弃策略会悄悄抛弃该任务) , DiscardOldestPolicy(抛弃最旧的策略则会抛弃下一个将被执行的任务,然后尝试重新提交新的任务)。
在构建高可靠的应用程序时,有界队列是一种强大的资源管理工具:它们能抑制并防止产生过多的工作项,使应用程序在负荷过载的情况下变得更加健壮。
LinkedBlockingQueue 和 ArrayBlockingQueue 是 FIFO 对列。PriorityBlockingQueue是一个按优先级排序的队列。SynchronousQueue没有存储空间,维护一组线程,这些线程在等待着把元素加入或移出队列。
核心线程数和最大线程数的大小定义:
private static final int CPU_COUNT = Runtime.getRuntime().availableProcessors();
private static final int CORE_POOL_SIZE = Math.max(2, Math.min(CPU_COUNT - 1, 4));
private static final int MAXIMUM_POOL_SIZE = CPU_COUNT * 2 + 1;
当核心线程处于闲置状态时是怎样的?
22. 用代码写一下生产者和消费者模式?
使用BlockingQueue:
BlockingQueue<String> queue = new LinkedBlockingQueue<>();//存储任务的队列
//生产者
Thread producer = new Thread(new Runnable() {
@Override
public void run() {
try {
queue.put("product");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
//消费者
Thread consumer = new Thread(new Runnable() {
@Override
public void run() {
try {
String product = queue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
start();
}
});
private void start(){
consumer.start();//开始
producer.start();
}
使用wait()和notify():
private static final int MAX_COUNT = 10;
private int count = 0;
private Object lock = new Object();
private void startTask() {
if (count < MAX_COUNT) {
count++;
executor.submit(consumerThread);
executor.submit(productThread);
} else {
executor.shutdown();
}
}
private LinkedList<String> products = new LinkedList<String>();
private ExecutorService executor = Executors.newCachedThreadPool();
Runnable productThread = new Runnable() {
@Override
public void run() {
synchronized (lock) {
products.offer("product no:" + count);
lock.notify();
}
}
};
Runnable consumerThread = new Runnable() {
@Override
public void run() {
synchronized (lock) {
try {
if (products.peek() == null) {
lock.wait();
}
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("take a product:" + products.poll());
startTask();
}
}
};
23. 无限创建线程的不足?
- 线程的生命周期的开销非常高:线程的创建和销毁是有代价的。
- 资源消耗:活跃的线程会消耗系统资源,尤其是内存。
- 稳定性:在可创建线程的数量上存在一个限制,随平台的不同而不同。
24. 枚举为什么是消耗内存的?
枚举本质上是通过普通的类来实现的,只是编译器为我们进行了处理。每个枚举类型都继承自java.lang.Enum,并且自动添加了values和value方法。而每个枚举常量是一个静态常量字段,使用内部类实现,该内部类继承了枚举类。所以枚举常量都通过静态代码块来进行。
25. BlockingQueue , CountDownLatch , FutureTask , Semaphore , Barrier类的了解?
- BlockingQueue:BlockingQueue扩展了Queue,增加了可阻塞的插入和获取等操作。如果队列为空,那么获取元素的操作将一直阻塞,直到队列中出现了一个可用的元素。如果队列已满(对于有界队列来说),那么插入元素的操作将一直阻塞,直到队列中出现可用的空间。在“生产者-消费者“这种设计模式中,阻塞队列是非常有用的。
- PriorityBlockingQueue:一个优先级排序的队列。
- SynchronousQueue:它维护一组线程,这些线程在等待着把元素加入或移除。
- CountDownLatch:是一种灵活的闭锁实现,它可以使一个或多个线程等待一组事件发生。 countDown方法递减计算器,表示有一个事件已经发生了,而await方法等待计数器达到零,这表示所有需要等待的事件都已经发生。如果计数器的值非零,那么await会一直阻塞直到计数器为零,或者等待中的线程中断,或者等待超时。
- Semaphore(信号量):管理一组虚拟的许可,在执行操作时可以首先获得许可,并在使用以后释放许可。如果没有许可,那么accquire将阻塞直到有许可。
- Barrier(栅栏):阻塞一组线程直到某个事件发生。所有的线程同时到达栅栏位置,才能继续执行。
- FutureTask也可以做闭锁。有3中状态:等待运行、正在运行、运行完成。Future.get()的行为取决于任务的状态。如果任务已经完成,那么get会立即返回结果,否则get将阻塞直到任务进入完成状态,然后返回结果或者抛出异常。Callable表示的任务可以抛出受检查的或未受检查的异常,并且任何代码可能抛出一个Error。
26. 写一个死锁?如何避免死锁?
死锁原因:两个线程试图以不同的顺序来获得相同的锁。
//容易发生死锁
public class LeftRightDeadLock{
private final Object left = new Object();
private final Object right = new Object();
public void leftRight(){
synchronized(left){
synchronized(right){
doSomething();
}
}
}
public void rightLeft(){
synchronized(right){
synchronized(left){
doSomething();
}
}
}
}
A → 锁住left → 尝试锁住right → 永久等待 B → 锁住right → 尝试锁住left → 永久等待
如何避免死锁?
支持定时的锁:使用Lock类的定时tryLock功能来代替内置锁机制。当使用内置锁时,只要没有获得锁,就会永远等待下去,而显示锁则可以指定一个超时时限(Timeout),在等待超时时间后tryLock会返回一个失败消息。
死锁的诊断:通过线程转储信息来分析死锁。
27. 注解
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
注解分类:
- @Retention:表示注解保留到哪个阶段。
- @Target:表示该注解可以用于什么地方。
- @Documented:表示将注解包含在 Javadoc 中。
- @Inherite:表示允许子类继承父类中的注解。
@RetentionPolicy中的参数说明:
- SOURCE:注解将被编译器丢弃。
- CLASS:注解在class文件中可用,但会被VM丢弃。
- RUNTIME:VM将在运行期间保留注解,因此可以通过反射机制读取注解的信息。
@Target中的ElementType参数值说明:
- TYPE:类、接口(包括注解类型)或enum声明
- FIELD:域声明(包括enum实例)
- METHOD:方法声明
- PARAMETER:参数声明
- CONSTRUCTOR:构造函数声明
- LOCAL_VARIABLE:局部变量声明
- ANNOTATION_TYPE:注解类型声明
- PACKAGE:包声明
- TYPE_PARAMETER:类型参数(在1.8中添加)
- TYPE_USE:类型使用(在1.8中添加)
28.线程的生命周期
| 状态 | 含义 | 典型触发方法/场景 |
|---|---|---|
| NEW | 线程对象已创建,但未调用 start() | Thread t = new Thread() |
| RUNNABLE | 可运行状态:已调用 start(),正在等待 CPU 时间片,或正在运行 | t.start() 后 |
| BLOCKED | 被 synchronized 锁阻塞,等待获取锁 | 进入同步块失败:synchronized |
| WAITING | 无限期等待,被动等待某个条件触发 | wait()、join()(无超时)、LockSupport.park() |
| TIMED_WAITING | 有限时间等待,超时后自动恢复 | sleep()、wait(timeout)、join(timeout)、parkNanos() |
| TERMINATED | 线程已运行结束(正常或异常) | run() 执行完毕 或 异常中止 |
29. 为什么成员内部类可以直接访问外部类的成员?Java 1.8 之前为什么方法内部类和匿名内部类访问局部变量和形参时必须加 final?
30. 为什么成员内部类可以直接访问外部类的成员?非静态内部类,静态内部类,匿名内部类的区别?
非静态内部类,静态内部类,匿名内部类的区别:
非静态内部类:
- 内部类中的变量和方法不能声明为静态的。
- 内部类实例化:B是A的内部类,实例化B:A.B b = new A().new B()。
- 内部类可以引用外部类的静态或者非静态属性及方法。
静态内部类:
- 静态内部类属性和方法可以声明为静态的或者非静态的。
- 实例化静态内部类:B是A的静态内部类,A.B b = new A.B()。
- 静态内部类只能引用外部类的静态的属性及方法。
匿名内部类:
- 匿名内部类也就是没有名字的内部类
- 匿名内部类只能使用一次
- 必须继承一个父类或实现一个接口
31.为什么 Java 中只有值传递?
- 一个方法不能修改一个基本数据类型的参数(即数值型或布尔型)。
- 一个方法可以改变一个对象参数的状态(数组和对象引用)。
- 一个方法不能让对象参数引用一个新的对象。
32.Java Object中有哪些方法?equals和hashCode方法什么时候会被重写?
Object:
package java.lang;
import dalvik.annotation.optimization.FastNative;
public class Object {
private transient Class<?> shadow$_klass_;
private transient int shadow$_monitor_;
public final Class<?> getClass() {
return shadow$_klass_;
}
public int hashCode() {
return identityHashCode(this);
}
// Android-changed: add a local helper for identityHashCode.
// Package-private to be used by j.l.System. We do the implementation here
// to avoid Object.hashCode doing a clinit check on j.l.System, and also
// to avoid leaking shadow$_monitor_ outside of this class.
/* package-private */ static int identityHashCode(Object obj) {
int lockWord = obj.shadow$_monitor_;
final int lockWordStateMask = 0xC0000000; // Top 2 bits.
final int lockWordStateHash = 0x80000000; // Top 2 bits are value 2 (kStateHash).
final int lockWordHashMask = 0x0FFFFFFF; // Low 28 bits.
if ((lockWord & lockWordStateMask) == lockWordStateHash) {
return lockWord & lockWordHashMask;
}
return identityHashCodeNative(obj);
}
private static native int identityHashCodeNative(Object obj);
public boolean equals(Object obj) {
return (this == obj);
}
private native Object internalClone();
public String toString() {
return getClass().getName() + "@" + Integer.toHexString(hashCode());
}
public final native void notify();
public final void wait(long millis) throws InterruptedException {
wait(millis, 0);
}
public final native void wait(long millis, int nanos) throws InterruptedException;
public final native void wait() throws InterruptedException;
protected void finalize() throws Throwable { }
protected Object clone() throws CloneNotSupportedException {
if (!(this instanceof Cloneable)) {
throw new CloneNotSupportedException("Class " + getClass().getName() +
" doesn't implement Cloneable");
}
return internalClone();
}
}
hashCode():为对象返回的一个哈希码值,对于哈希表有重要作用。
clone(): 浅拷贝:对象中的引用的其它对象还是指向原来的地址;深拷贝:对象中的引用的其它对象指向新的地址。
finalize 和 clone 是 protect 修饰。
Android
考察Android知识时,会偏向于一些高级知识,比如:Activity的启动过程, View绘制原理,View事件原理,消息机制原理等。
1. 说说Activity的四种启动模式?在Service中可以打开一个Activity吗?
- standard:标准模式,也是系统默认模式。每次启动一个Activity都会重新创建一个新的实例,不管这个实例是否存在。被创建的实例的生命周期符合典型的Activity的生命周期onCreate → onStarat → onResume。在这种模式下,谁启动了这个Activity,那么这个Activity就运行在启动它的那个Activity所在的任务栈中。
- singleTop:栈顶复用模式(推送打开在栈顶的Activity)。在这种模式下,如果新Activity已经位于任务栈的栈顶,那么此Activity不会被重新创建,同时它的onNewIntent方法会被调用。但这个Activity的onCreate, onStart方法不会被调用。
- singleTask:栈内复用模式。在这种模式下,只有Activity在一个栈中存在,那么多次启动Activity都不会创建实例,和singleTop一样,系统会调用其onNewIntent方法。
- singInstance:单例模式。这种模式下的Activity存在于一个独立的任务栈中。这个实例一旦创建,后续的请求均不会创建新的Activivty,除非这个独特的任务栈被系统销毁。
当TaskAffinity 和 allowTaskReparenting 结合的时候,这种情况比较复杂,会产生特殊的效果。当一个应用A启动了应用B的某个 Activity 后,此Activity 的 allowTaskReparenting 属性为true的话,那么当应用 B 被启动后,此Activity会直接从 A的任务栈移动到应用 B 的任务栈。
TaskAffinity 属性主要和 singleTask 启动模式或者 allowTaskReparenting 属性配对使用,其他情况下没有意义。
在Service中不可以使用context打开一个Activity,因为standard模式的Activity模式会进入启动它的Activity所属的任务栈中,但是非Activity类型的context并没有所谓的任务栈。解决这个问题的方法是为待启动Activity指定FLAG_ACTIVITY_NEW_TASK标记位。
在singleInstance模式下的Activity中启动一个standard模式的Activity,这个standard模式的Activity会存在于一个新的任务栈中。
有三个Activity,分别为A B C,B 的启动模式是SingleInstance,其它的是Standard,A启动B,B再启动C,再按返回键,会发生什么?
会从Activity C 直接退回到 Activity A,Activity A 再 退回到 Activity B。
2. Activity A打开Activity B时,AB生命周期的变化?
第一步:A → onPause 第二步:B → onCreate → onStart → onResume 第三步:A → onStop
如果被启动的Activity B 设置了透明主题。生命周期变化是:
第一步:A → onPause 第二步:B → onCreate → onStart → onResume
Activity A 只会进入onPause 状态。
3. Activity,Service,BroadcastReceiver,ContentProvider的启动过程?
Activity:
- Activity → startActivity → startActivityForResult →
- Instrumentation → execStartActivity → ActivityTaskManagerService(extends IActivityTaskManager.Stub)
- ActivityMangerService(extends IActivityManager.Stub) → startActivity →
- ActivityStackSupervisor → ActivityStack →
- ApplicationThread(extends IApplicationThread.Stub) → scheduleLaunchActivity →
- ActivityThread → handleLaunchActivity → performLaunchActivity
performLaunchActivity这个方法主要完成的事情:
- 从ActivityRecordClient 中获取待启动的Activity的组件信息
- 通过Instrumentation的newActivity方法使用类加载器创建Activity对象
- 通过LoadedApk 的makeApplication方法尝试创建Application对象
- 创建ContextImpl对象并通过Activity的attach方法来完成一些重要数据的初始化
- 调用Activity的 onCreate 方法
ActivityStack[[TaskRecord[ActivityRecord]],[TaskRecord[ActivityRecord]] Activity的生命周期状态存储在:ActivityThread#ActivityClientRecord中,状态类ActivityLifecycleItem Activity的启动模式存储在:ActivityRecord
BroadcastReceiver:
注册:
Context → registerReceiver → ContextImpl → registerReceiver → registerReceiverInner → (BroadcastReceiver → ReceiverDispather.InnerReceiver(extends IIntentReceiver.Stub)) →
ActivityMangerService → registerReceiver → (把远程的 InnerReceiver 和 IntentFilter 对象存储起来)
发送和接收:
Context → sendBroadcast → ContextImpl → sendBroadcast →
ActivityMangerService → broadcastIntent → broadcastIntentLocked → (根据 intent-filter 查找匹配的广播接收者并将满足条件的广播接收者添加到 BroadcastQueue中)→
BroadcastQueue → scheduleBroadcastsLocked → processNextBroadcast → (无序广播存储在 mParallelBroadcasts 中) → deliverToRegisteredReceiverLocked → performReceiverLocked →
ApplicationThread → scheduleRegisteredReceiver →
InnerReceiver → performReceiver →
ReceiverDispather → performReceiver →
ActivityThread → post → Args →
Broadcast → onReceive
Service:
startService →
- Contex → startService → ContextImpl → startService → startServiceCommon →
- ActivityMangerService → startService →
- ActiveServices → ServiceRecord →
- ApplicationThread → scheduleCreateService →
- ActivityThread → handleCreateService
handleCreateService主要完成的事情:
- 首先通过类加载器创建 Service 的实例
- 创建 Application 对象并调用 其 onCreate ,当然 Application 的创建过程只有一次。
- 创建 ContextImpl对象并通过Service的attach方法建立二者之间的关系,这个过程和Activity实际上是类似的,毕竟Service 和 Activity 都是一个Context。
- 调用Service的onCreate方法并将Service对象存储到ActivityThread中的一个列表中。
bindService →
- Context → bindService → ContextImpl → bindService → bindServiceConnection → (ServiceConnection → ServiceDispather.InnerConnection) → bindServiceCommon →
- ActivityMangerService → bindService →
- ActiveServices → bindServiceLocked…→
- ApplicationThread → scheduleBindService →
- ActivityThread → handleBindService →
- ActivityMangerService → publishService →
- ActiveServices → publishServiceLocked →
- ServiceDispather → connect →
- ActivityThread → post → RunConnection →
- ServiceDispather → doConnected → ServiceConnection
ContentProvider:
首先会调用ActivityThread的acquireProvider 方法,如果存在ContentProvider对象就直接返回,否则就发送一个进程间请求给AMS让其启动目标ContentProvider。
启动目标ContentProvider:
- ActivityThread → main → attach →
- ApplicationThread → ActivityMangerService → attachApplication →
- ApplicationThread → bindApplication →
- ActivityThread → handBindApplication
执行完handBindApplication方法接着会:
- 创建ContextImpl 和 Instrumentation
- 创建 Application 对象
- 启动当前进程的 ContentProvider 并调用其onCreate 方法
- 调用 Application 的 onCreate 方法
除了 onCreate 方法由系统回调并运行在主线程里,其它五个方法均由外界回调并运行在Binder线程池中。
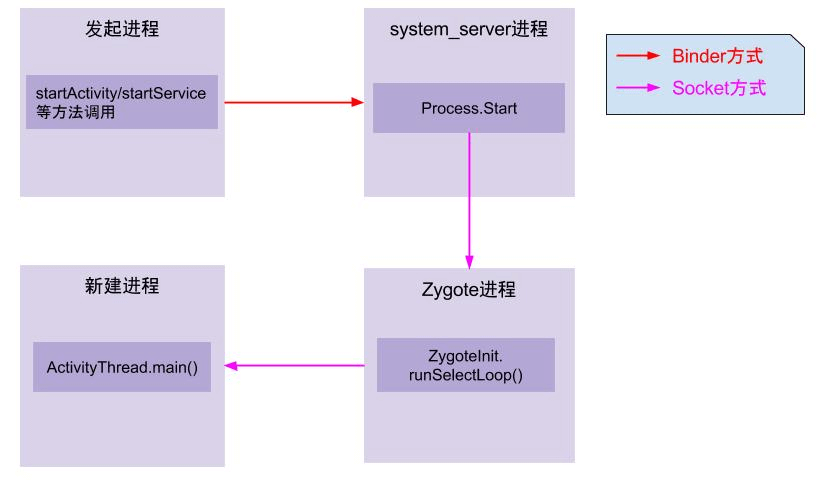
- App发起进程:当从桌面启动应用,则发起进程便是Launcher所在进程;当从某App内启动远程进程,则发送进程便是该App所在进程。发起进程先通过binder发送消息给system_server进程;
- system_server进程:调用Process.start()方法,通过socket向zygote进程发送创建新进程的请求;
- zygote进程:在执行ZygoteInit.main()后便进入runSelectLoop()循环体内,当有客户端连接时便会执行ZygoteConnection.runOnce()方法,再经过层层调用后fork出新的应用进程;
- 新进程:执行handleChildProc方法,最后调用ActivityThread.main()方法;
- ActivityThread → main → attach → ActivityMangerService → attachApplication → ApplicationThread → bindApplication → ActivityThread → handBindApplication;
- 创建ContextImpl 和 Instrumentation 对象,创建 Application 对象,启动当前进程的 ContentProvider 并调用其onCreate 方法,调用 Application 的 onCreate 方法。
4. Activity 与 Service 之间如何通信?Fragment 与 Fragment之间如何通行?
5. onSaveInstanceState和onRestoreInstanceState方法的调用时机?
onSaveInstanceState方法会被调用的情况:
- 当用户按下HOME键时。
- 从最近应用中选择运行其他的程序时。
- 按下电源按键(关闭屏幕显示)时。
- 从当前activity启动一个新的activity时。
- 屏幕方向切换时(无论竖屏切横屏还是横屏切竖屏都会调用)。
onSaveInstanceState方法的调用时机,
在onPuase方法中:handlePauseActivity → performPauseActivity →
// Next have the activity save its current state and managed dialogs...
if (!r.activity.mFinished && saveState) {
callCallActivityOnSaveInstanceState(r);
}
判断是否调用onSaveInstanceState方法的前提条件有两个:一、Activity是否mFinished;二、saveState是否为true,在handlePauseActivity方法中,这个值的取决于当前系统版本是否低于3.0,如果低于3.0就为true,否则为false。
public boolean isPreHoneycomb() {
if (activity != null) {
return activity.getApplicationInfo().targetSdkVersion
< android.os.Build.VERSION_CODES.HONEYCOMB;
}
return false;
}
另外mFinished的值取决于Activity是否调用了finish方法,如果是mFinished就会true,否则为false。
在onSop方法中:handleStopActivity → performStopActivityInner →
// Next have the activity save its current state and managed dialogs...
if (!r.activity.mFinished && saveState) {
if (r.state == null) {
callCallActivityOnSaveInstanceState(r);
}
}
判断是否调用onSaveInstanceState方法的前提条件也有两个:一、Activity是否mFinished;二、saveState是否为true,在handleStopActivity方法中,这个值传递的就为true。
总之,判断是否调用onSaveInstanceState方法,首先会判断Activity有没有mFinished,如果Activity调用了finish()方法,mFinished就会true,否则为false;其次会先在onPause方法判断当前系统版本是否低于3.0,如果是saveState变量就为true,否则为false。然后会在onStop方法中将saveState赋值为true。
- 在系统版本3.0以前,会在调用onPuase方法前,调用onSaveInstanceState方法。
- 在系统版本3.0以后,9.0以前,会在调用onPause方法后,调用onStop方法前,调用onSaveInstanceState方法。
- 在系统版本9.0以后,会在调用onStop方法后,调用onSaveInstanceState方法。
onRestoreInstanceState方法的调用时机在onStart和onPostCreate方法之间,onCreate和onRestoreInstanceState方法都会接受onSaveInstanceState方法保存的Bundle对象值。
| 另外,如果Activity的** android:stateNotNeeded=”true | false” **属性为true,onSaveInstanceState在任何情况都不会被调用;false为默认值,保存Activity的状态。 |
6. Activity,Fragment,Service的生命周期?
Activity: onCreate → onStart → onResume → onPause → onStop → onDestory
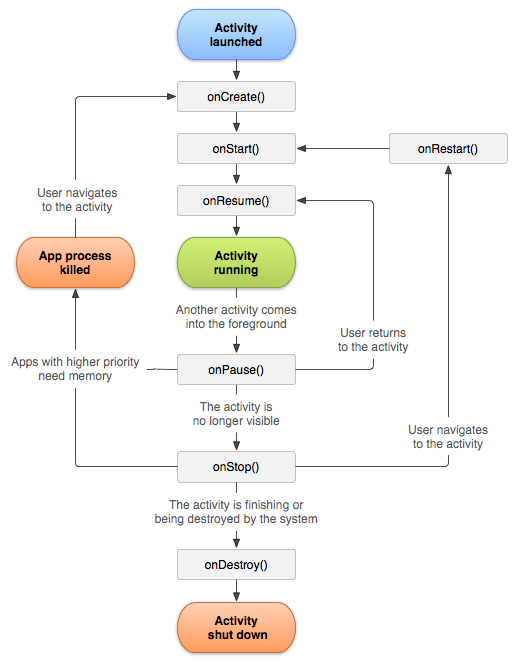
屏幕旋转对生命周期的影响:
| 设备 | HuaWei:9.0 | OPPO |
|---|---|---|
| 不设置android:configChanges | Activity会重建,生命周期方法会重新调用一次 | |
| 设置android:configChanges=”orientation” | Activity生命周期方法不会调用 | |
| 设置android:configChanges=”orientation | keyboardHidden” | Activity生命周期方法不会调用 |
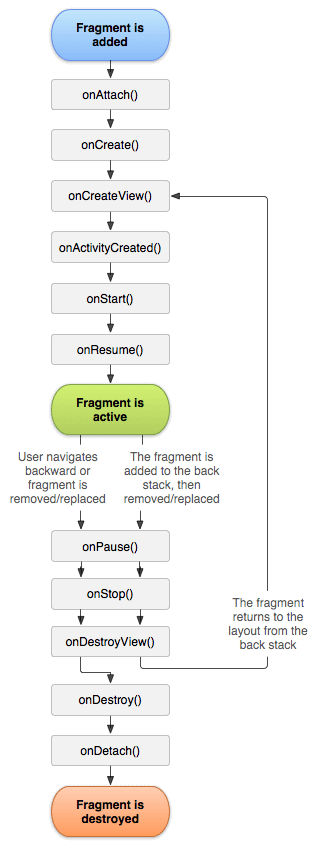
Fragment: onAttach → onCreate → onCreateView → onActivityCreate → onStart → onResume → onPause → onStop → onDestoryView → onDestory → onDetach
Service :
- → startService → onCreate → onStartCommand → onDestroy
- → bindService → onCreate → onBind → onUnBind → onDestory
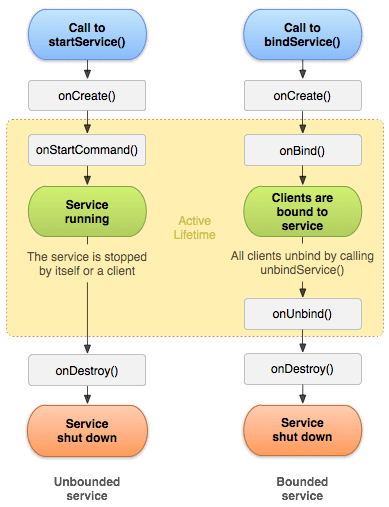
startService:多次调用,只会执行一次 onCreate ,但会执行多次onStartCommand。 bindService:多次调用,onCreate 和 onBind 都只会执行一次。
7. Service与Thread(进程是资源分配的最小单位,线程是CPU调度的最小单位)的区别?
8. View的绘制原理?
View的绘制过程是从 ViewRootImpl 的 performTraversals 方法开始的(通过Choreographer.FrameCallback的回调调用performTraversals),它经过measure、layout和draw 三个过程最终将一个 View 绘制出来,其中 measure 用来测量 View 的宽和高,layout 用来确定 View 在父容器中的放置位置,而 draw 则负责将 View 绘制在屏幕上。
void scheduleTraversals() {
if (!mTraversalScheduled) {
mTraversalScheduled = true;
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
if (!mUnbufferedInputDispatch) {
scheduleConsumeBatchedInput();
}
notifyRendererOfFramePending();
pokeDrawLockIfNeeded();
}
}
final class TraversalRunnable implements Runnable {
@Override
public void run() {
doTraversal();
}
}
final TraversalRunnable mTraversalRunnable = new TraversalRunnable();
void doTraversal() {
if (mTraversalScheduled) {
mTraversalScheduled = false;
mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);
if (mProfile) {
Debug.startMethodTracing("ViewAncestor");
}
performTraversals();
if (mProfile) {
Debug.stopMethodTracing();
mProfile = false;
}
}
}
1.mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
2.doTraversal();
3.performTraversals();
View → ViewRootImpl → performTraversals →
- performMeasure → measure → onMeasure
- performLayout → layout → onLayout
- performDraw → draw → onDraw
MeasureSpec是测量规格,由SpecSize(某种测量模式下的规格大小)和SpecMode(测量模式)组成。
SpecMode有三类:
- UNSPECIFIED:父容器不对View有任何限制,要多大给多大,这种情况一般用于系统内部,表示一种测量的状态。
- EXACTLY:父容器已经检测出View所需要的精确大小,这个时候View的最终大小就是SpecSize指定的值。它对应于LayoutParams中的match_parent和具体的数值这两种模式。
- AT_MOST:父容器指定了一个可用大小即SpecSize,View的大小不能大于这个值,具体是什么要看不同View的具体实现。它对应于LayoutParams中的wrap_content。
普通View的MeasureSpec的创建规则:
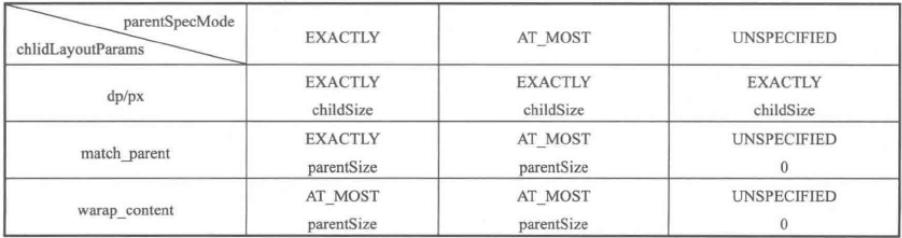
子元素的MeasureSpec的创建与父容器的MeasureSpec和子元素本身的LayoutParams有关,此外还和View的margin及padding有关。
View的measure过程:
//测量View的大小
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
setMeasuredDimension(getDefaultSize(getSuggestedMinimumWidth(), widthMeasureSpec),
getDefaultSize(getSuggestedMinimumHeight(), heightMeasureSpec));
}
//获得推荐最小大小
protected int getSuggestedMinimumWidth() {
return (mBackground == null) ? mMinWidth : max(mMinWidth, mBackground.getMinimumWidth());
}
//获得默认大小
public static int getDefaultSize(int size, int measureSpec) {
int result = size;
int specMode = MeasureSpec.getMode(measureSpec);
int specSize = MeasureSpec.getSize(measureSpec);
switch (specMode) {
case MeasureSpec.UNSPECIFIED:
result = size; //获得推荐最小大小
break;
case MeasureSpec.AT_MOST:
case MeasureSpec.EXACTLY:
result = specSize; //测量大小
break;
}
return result;
}
//设置View宽高的测量值
protected final void setMeasuredDimension(int measuredWidth, int measuredHeight) {
boolean optical = isLayoutModeOptical(this);
if (optical != isLayoutModeOptical(mParent)) {
Insets insets = getOpticalInsets();
int opticalWidth = insets.left + insets.right;
int opticalHeight = insets.top + insets.bottom;
measuredWidth += optical ? opticalWidth : -opticalWidth;
measuredHeight += optical ? opticalHeight : -opticalHeight;
}
setMeasuredDimensionRaw(measuredWidth, measuredHeight);
}
getSuggestedMinimumWidth方法:如果View没有设置背景,那么返回android:minWidth这个属性所指定的值,这个值可以为0;如果View设置了背景,则返回android:minWidth和背景的最小宽度这两者的最大值,getSuggestedMinimumWidth和getSuggestMinimumHeight的返回值是View在UNSPECIFIED情况下的测量宽/高。
getDefaultSize方法:View的宽高由specSize决定,所以继承View的自定义控件需要重写onMeasure方法并设置wrap_content时自身大小,否则在布局中使用wrap_content就相当于使用match_parent。
View 的measure过程是三大流程中最复杂的一个,measure完成以后,通过getMeasuredWidth/Height方法就可以正确地获取到View的测量宽/高。需要注意的是,在某些极端情况下,系统可能需要多次 measure 才能确定最终的宽/高,在这种情形下,在onMeasure方法中拿到的宽/高很可能是不准确的。一个比较好的习惯是在 onLayout 方法中获取View的测量宽/高或者最终宽/高。
View的layout过程:
public void layout(int l, int t, int r, int b) {
......
boolean changed = isLayoutModeOptical(mParent) ?
setOpticalFrame(l, t, r, b) : setFrame(l, t, r, b);
......
onLayout(changed, l, t, r, b);
......
}
//默认为空实现
protected void onLayout(boolean changed, int left, int top, int right, int bottom) {
}
//确定mLeft,mRight,mTop,mBottom的值
protected boolean setFrame(int left, int top, int right, int bottom) {
boolean changed = false;
if (DBG) {
Log.d("View", this + " View.setFrame(" + left + "," + top + ","
+ right + "," + bottom + ")");
}
if (mLeft != left || mRight != right || mTop != top || mBottom != bottom) {
changed = true;
// Remember our drawn bit
int drawn = mPrivateFlags & PFLAG_DRAWN;
int oldWidth = mRight - mLeft;
int oldHeight = mBottom - mTop;
int newWidth = right - left;
int newHeight = bottom - top;
boolean sizeChanged = (newWidth != oldWidth) || (newHeight != oldHeight);
// Invalidate our old position
invalidate(sizeChanged);
mLeft = left;
mTop = top;
mRight = right;
mBottom = bottom;
mRenderNode.setLeftTopRightBottom(mLeft, mTop, mRight, mBottom);
mPrivateFlags |= PFLAG_HAS_BOUNDS;
if (sizeChanged) {
sizeChange(newWidth, newHeight, oldWidth, oldHeight);
}
if ((mViewFlags & VISIBILITY_MASK) == VISIBLE || mGhostView != null) {
// If we are visible, force the DRAWN bit to on so that
// this invalidate will go through (at least to our parent).
// This is because someone may have invalidated this view
// before this call to setFrame came in, thereby clearing
// the DRAWN bit.
mPrivateFlags |= PFLAG_DRAWN;
invalidate(sizeChanged);
// parent display list may need to be recreated based on a change in the bounds
// of any child
invalidateParentCaches();
}
// Reset drawn bit to original value (invalidate turns it off)
mPrivateFlags |= drawn;
mBackgroundSizeChanged = true;
if (mForegroundInfo != null) {
mForegroundInfo.mBoundsChanged = true;
}
notifySubtreeAccessibilityStateChangedIfNeeded();
}
return changed;
}
/**
* Return the width of the your view.
*
* @return The width of your view, in pixels.
*/
@ViewDebug.ExportedProperty(category = "layout")
public final int getWidth() {
return mRight - mLeft;
}
/**
* Return the height of your view.
*
* @return The height of your view, in pixels.
*/
@ViewDebug.ExportedProperty(category = "layout")
public final int getHeight() {
return mBottom - mTop;
}
layout方法:首先通过setFrame方法来设定View的四个顶点的位置,即初始化mLeft、mRight、mTop和mBottom这四个值,View的四个顶点一旦确定,那么View在父容器中的位置也就确定了;接着会调用onLayout方法 ,这个方法的用途是父容器确定子元素的位置,和onMeasure方法类似,onLayout的具体实现同样和具体的布局有关,所以View和ViewGroup均没有真正实现onLayout方法。
| View | ViewGroup(抽象类) | |
|---|---|---|
| measure | 是一个final方法,在measure中测量自己后,调用onMeasure | 不能重写 |
| onMeasure | 是一个非final方法 | 没有重写onMeasure,提供了一个measureChildren方法完成子View的测量 |
| layout | 是一个非final方法,在layout中测量自己后,调用onLayout | 重写了layout方法,并在layout中调用super.layout |
| onLayout | 是一个非final的空方法 | 重写了onLayout |
View的draw过程:
- 绘制背景background.draw(canvas)
- 绘制自己(onDraw)
- 绘制children(dispatchDraw)
- 绘制装饰(onDrawSrcollBars)
View绘制过程的传递是通过dispatchDraw来实现的,dispatchDraw会遍历调用所有子元素的draw方法。
View有一个特殊的方法setWillNotDraw:
/**
* If this view doesn't do any drawing on its own, set this flag to
* allow further optimizations. By default, this flag is not set on
* View, but could be set on some View subclasses such as ViewGroup.
*
* Typically, if you override {@link #onDraw(android.graphics.Canvas)}
* you should clear this flag.
*
* @param willNotDraw whether or not this View draw on its own
*/
public void setWillNotDraw(boolean willNotDraw) {
setFlags(willNotDraw ? WILL_NOT_DRAW : 0, DRAW_MASK);
}
如果一个View不需要绘制任何内容,那么设置这个标记为true以后,系统会进行相应的优化。
自定义View需要注意的事项:
- 让View支持wrap_content:因为直接继承View或者ViewGroup的控件,如果不在onMeasure中对wrap_content做特殊处理,那么当外界在布局中使用wrap_content时就无法达到预期的效果。
- 如果有必要,让View支持padding:如果不在draw方法中处理padding,那么padding属性是无法起作用的。另外,直接继承自ViewGroup的控件需要在onMeasure和onLayout中考虑padding和子元素的margin对其造成的影响,不然将导致padding和子元素的margin失效。
- 尽量不要在View中使用Handler,没必要:因为View内部本身提供了post系列的方法,完全可以替代Handler的作用,当然除非你很明确要使用Handler来发送消息。
- View中如果有线程或者动画,需要及时停止,参考View#onDetachViewFromWindow
- View带有滑动嵌套情形时,需要处理好滑动冲突
VISIBLE → INVISIBLE : invalidate VISIBLE → GONE : requestLayout
9. View的事件处理?
public boolean dispatchTouchEvent(MotionEvent ev)
用来进行事件的分发。如果事件能够传递给当前View,那么此方法一定会被调用,返回结果受当前View的onTouchEvent和下级View的dispatchTouchEvent方法的影响,返回结果值 true 表示当前 View 处理这个事件,false不处理。
public boolean onInterceptTouchEvent(MotionEvent ev)
在上述方法内部调用,用来判断是否拦截某个事件,如果当前View拦截了某个事件,那么在同一个事件序列当中,此方法不会被再次调用,返回结果表示是否拦截当前事件。
public boolean onTouchEvent(MotionEvent ev)
在dispatchTouchEvent方法中调用,用来处理点击事件,返回结果表示是否消耗当前事件,如果不消耗,则在同一个事件序列中,当前View无法再次接收到事件。
下面代码表达了它们的关系:
public boolean dispatchTouchEvent(MotionEvnet ev){
boolean consume = false;
if(onInterceptTouchEvent(ev){
consume = onTouchEvnet(ev);
}else{
consume = child.dispatchTouchEvent(ev);
}
return consume;
}
事件传递的规则:对于一个根ViewGroup来说,点击事件产生后,首先会传递给它,这时它的dispatchTouchEvent就会被调用,如果这个ViewGroup的onInterceptTouchEvent方法返回true就表示它要拦截当前事件,接着事件就会交给这个ViewGroup处理,即它的onTouchEvent方法就会被调用;如果这个ViewGroup的onInterceptTouchEvent返回false就表示不拦截当前事件,这时当前事件就会继续传递给它的子元素,接着子元素的dispatchTouchEvent方法就会被调用,如此反复知道事件被最终处理。
当一个View需要处理事件时,如果它设置了onTouchListener,那么onTouchListener中的onTouch方法会被回调。这时事件如何处理还要看onTouch的返回值,如果返回false,则当前View的onTouchEvent方法会被调用;如果返回true,那么onTouchEvent方法将不会被调用。
事件传递顺序:Activity → Window → View
事件序列以down事件开始,中间含有数量不定的move事件,最终以up事件结束。ACTION_DOWN → ACTION_MOVE → ACTION_UP。
关于ACTION_CANCEL 定义:当前手势被终止了,将不再接收触摸的点,应该把这个当作离开事件,但是不会执行 通常你想要的操作。
发生场景:事件被上层拦截了,一个完整的事件包含ACTION_DOWN → ACTION_MOVE → ACTION_UP。
事件冲突:外部拦截法,内部拦截发。
外部拦截法:
- 重写父 View 的 onInterceptTouchEvent 事件。
- 在 onInterceptTouchEvent 事件 中处理 ACTION_DOWN 这个事件时,要返回 false,因为返回 true ,后续子 View 就无法接收 ACTION_DOWN 和 ACTION_MOVE 事件了。
- 在 onInterceptTouchEvent 事件 中处理 ACTION_MOVE 这个事件时,根据选择来确定要不要拦截,父 View 要拦截就返回 true, 不拦截就返回 false。
- 在 onInterceptTouchEvent 事件 中处理 ACTION_UP 这个事件时,也要返回false,因为ACTION_UP 事件本身没有太大意义。
内部拦截发:
- 重写父 View 的 onInterceptTouchEvent 事件。
- 重写子 View 的 dispatchTouchEvent 事件。
- 在父 View 的 onInterceptTouchEvent 事件中处理 ACTION_DOWN 这个事件时,要返回 false。
- 在子 View 的 dispatchTouchEvent 事件中处理 ACTION_DOWN 这个事件时,告诉父 View 后面不要拦截事件,通过代码
parent.requestDisallowInterceptTouchEvent(true)来设置。 - 在子 View 的 dispatchTouchEvent 事件中处理 ACTION_MOVE 这个事件时,根据选择来确定是子 View 自己处理还是由父 View 来处理,如果是给父 View 处理,就通过代码
parent.requestDisallowInterceptTouchEvent(false)来设置。 - FLAG_DISALLOW_INTERCEPT:这个标记位是通过 requestDisallowInterceptTouchEvent方法来设置的,一般用于子View中。 FLAG_DISALLOW_INTERCEPT一旦设置后,ViewGroup将无法拦截除了ACTION_DOWN以外的其它点击事件。
- ACTION_DOWN不受FLAG_DISALLOW_INTERCEPT这个标记位的控制,所以一旦父容器拦截ACTION_DOWN事件,那么所有的事件都无法传递到子元素中去,这样内部拦截就无法传递起作用了。
10. 应用程序开启多进程会引起哪些?
- 静态成员和单例模式完全失效。-不是一块内存
- 线程同步机制完全失效。-不是一块内存
- SharedPreferences的可靠性降低。-同一时间操作不可靠
- Application会多次创建。
11. 如何实现进程间的通信?进程间通信的方式有哪些?Android进程的生命周期?
如何实现进程间的通信:Binder。
Linux 现有的所有进程间通信的方式:
管道:在创建时分配一个 page 大小的内存,缓存区大小比较有限;
消息队列:信息复制两次,额外的CPU消耗。不适合频繁或信息量大的通信;
共享内存:无须复制,共享缓冲区直接附加到进程虚拟地址空间,速度快;但进程间的同步问题操作系统无法实现,必须各进程利用同步工具解决。
套接字:作为更通用的接口,传输效率低,主要用于不通机器或跨网络的通信。
信号量:常作为一种锁机制,防止某进程正在访问共享资源时,其它进程也访问资源。因此,主要作为进程间以及同一进程内不同线程间的同步手段。
信号:不适用于信息交换,更适用进程中断控制,比如非法内存访问,杀死某个进程等。
进程的生命周期:前台进程,可见进程,服务进程,后台进程,空进程。
12. Binder原理?
从三方面说:
- Binder是Android中一种跨进程通信方式。
- 基于C/S结构,连接客户端进程、服务端进程和 ServiceManager 进程。
- API: IBinder接口和Binder类。在Android中可以通过以AIDL 和 Messenger 方式实现进程间的通信。
1.Binder是Android中一种跨进程通信方式
。Binder是ServiceManager连接各种Manager(ActivityManager , WindowManager等)和相应ManagerService的桥梁;从Android应用层来说,Binder是客户端和服务端进行通信的媒介,当bindService的时候,服务端返回一个包含了服务端业务调用的Binder对象,通过这个Binder对象,客户端就可以获取服务端提供的服务或者数据,这里的服务包括普通服务和基于AIDL的服务。
2.C/S结构 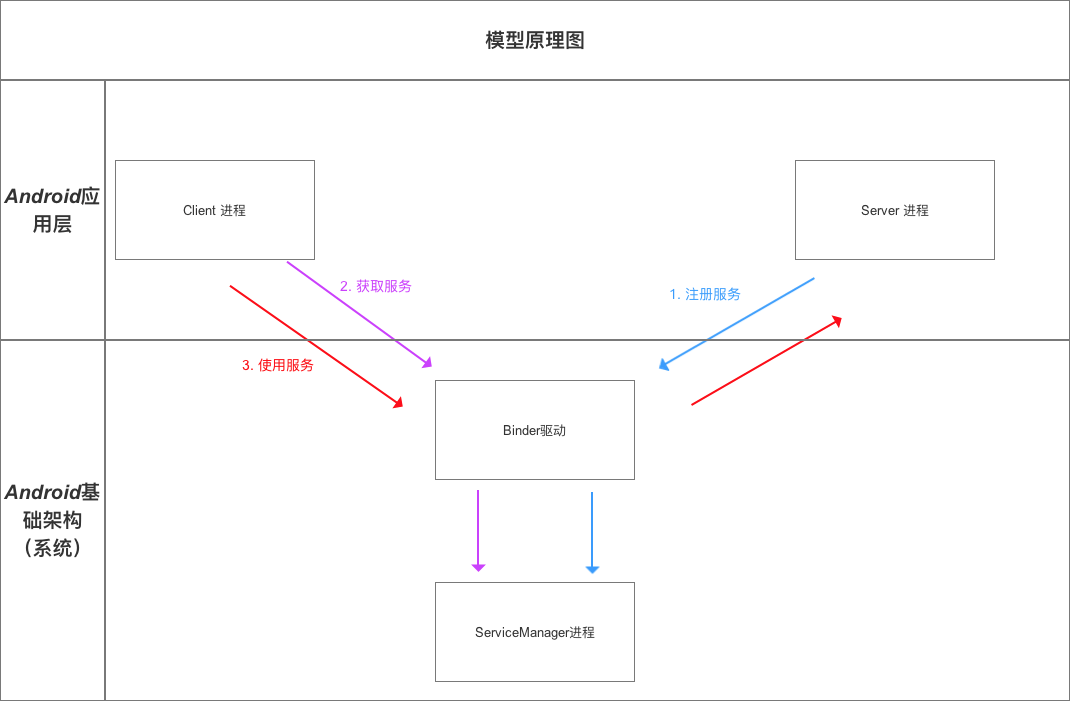
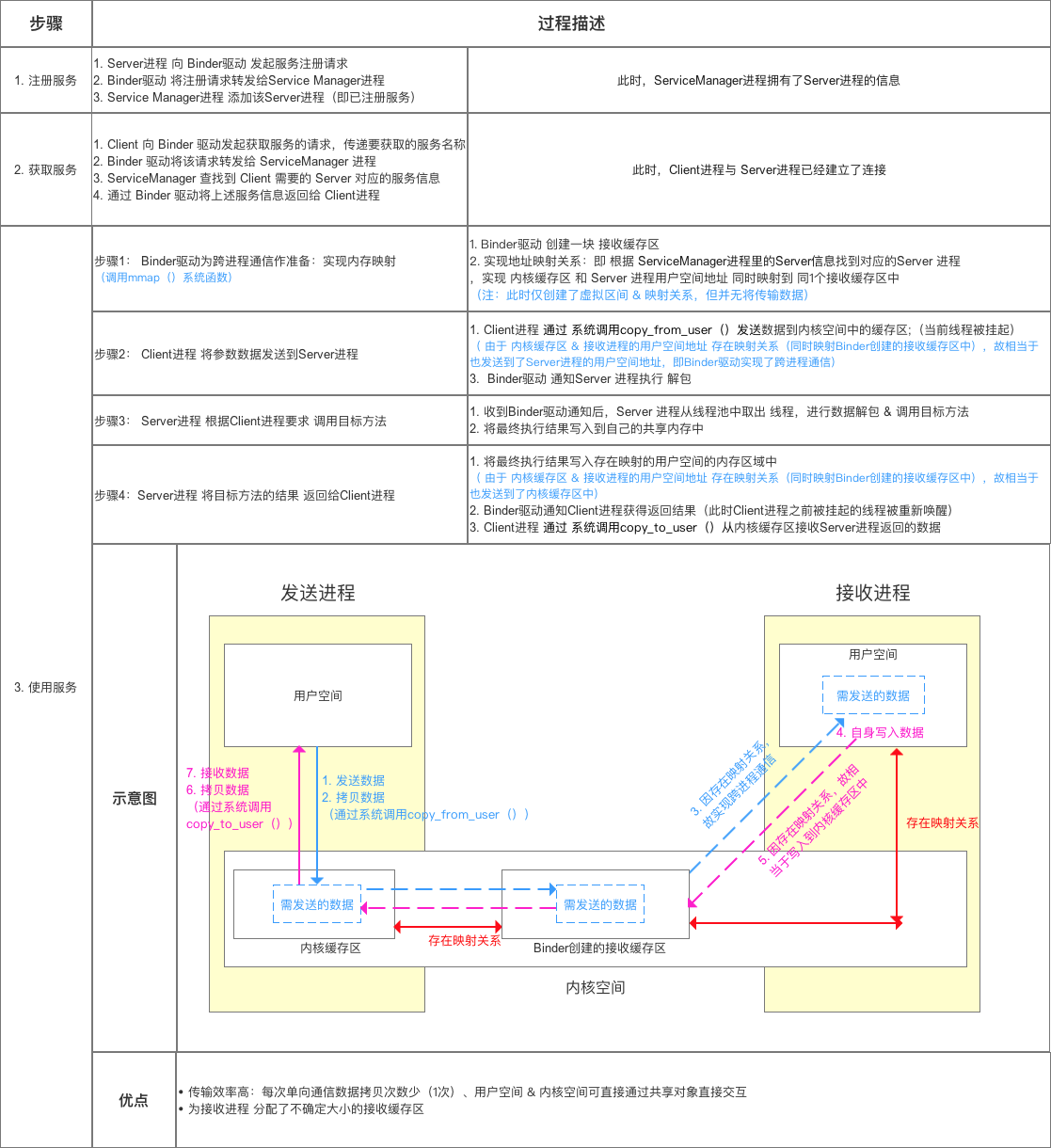 3.API
3.API
服务端接口:实际是Binder对象,该对象一旦创建,内部则会启动一个隐藏线程,会接受Binder驱动发送的消息,收到消息后,会执行Binder对象中的onTransact()函数,并按照该函数的参数执行不同的服务端代码。
protected boolean onTransact(int code, Parcel data, Parcel reply,
int flags) throws RemoteException {
}
Binder驱动:该对象也为Binder的实例,客户端通过该对象访问远程服务。
客户端接口:获得Binder驱动,调用其transact()发送消息至服务端。
/**
* Default implementation rewinds the parcels and calls onTransact. On
* the remote side, transact calls into the binder to do the IPC.
*/
public final boolean transact(int code, @NonNull Parcel data, @Nullable Parcel reply,
int flags) throws RemoteException {
if (false) Log.v("Binder", "Transact: " + code + " to " + this);
if (data != null) {
data.setDataPosition(0);
}
boolean r = onTransact(code, data, reply, flags);
if (reply != null) {
reply.setDataPosition(0);
}
return r;
}
- code:是一个整型的唯一标识,用于区分执行那个方法,客户端会传递此参数,告诉服务端执行哪个方法。
- data:客户端传递过去的参数。
- replay:服务端返回回去的值。
- flags:标明是否有返回值,0为有(双向),1为没有(单向)。
AIDL其实是通过我们写的aidl文件,帮助我们生成一个接口,一个Stub类用于服务端,一个Proxy类用于客户端调用。
使用Binder需要注意:
- 服务端要防止多个线程同时访问,可以使用并发处理。
- 注册和解注册使用RemoteCallbackList
- 进行权限验证
- 服务端运行在线程池中,客户端在UI线程中,容易ANR
13. 在多进程中如何让SharedPreferences同步?
14. 属性动画原理?
动画分类:帧动画(图片),补间动画(alpha,rotate,translate,scale),属性动画。
属性动画:时间插值器,估值器
- 时间插值器:根据时间的流逝的百分比计算出当前属性值改变的百分比。
- 估值器:根据当前属性值改变的百分比计算出改变后的属性值。
反射调用setXXX和getXXX方法
工作原理:属性动画要求动画作用的对象提供该属性的set方法,属性动画根据你传递的该属性的初始值和最终值,以动画的效果多次去调用set方法。每次传递给set方法的值都不一样,确切来说是随着时间的推移,所传递的值越来越接近最终值。如果动画的时候没有传递初始值,那么还要提供get方法,因为系统要去获取属性的初始值。
15. 消息机制原理?
Handler, Looper, MessageQueue, Message
16. Handler是如何发送一个延时消息的?
sendMessageDelayed:
/**
* Enqueue a message into the message queue after all pending messages
* before (current time + delayMillis). You will receive it in
* {@link #handleMessage}, in the thread attached to this handler.
*
* @return Returns true if the message was successfully placed in to the
* message queue. Returns false on failure, usually because the
* looper processing the message queue is exiting. Note that a
* result of true does not mean the message will be processed -- if
* the looper is quit before the delivery time of the message
* occurs then the message will be dropped.
*/
public final boolean sendMessageDelayed(Message msg, long delayMillis)
{
if (delayMillis < 0) {
delayMillis = 0;
}
return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);
}
nativePollOnce(ptr, nextPollTimeoutMillis):
//MessageQueue的next()方法中
//......
if (msg != null) {
if (now < msg.when) {
// Next message is not ready. Set a timeout to wake up when it is ready.
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// Got a message.
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
if (DEBUG) Log.v(TAG, "Returning message: " + msg);
msg.markInUse();
return msg;
}
}
//......
发送一个延时5s的消息,接着发送一个延时2s的消息?谁先执行,为什么?
MessageQueue 在 添加消息到队列(enqueueMessage)的时候,会比对执行时间来排序,所以延时2s的先执行。
在接着发送一个延时2s的消息后,又让线程睡1s,谁先执行,为什么? 答案和上面一样。
IdleHandler:IdleHandler 是 Handler 提供的一种在消息队列空闲时,执行任务的时机。但它执行的时机依赖消息队列的情况,那么如果 MessageQueue 一直有待执行的消息时,IdleHandler 就一直得不到执行,也就是它的执行时机是不可控的,不适合执行一些对时机要求比较高的任务。
同步屏障:设置了同步屏障之后,Handler只会处理异步消息。再换句话说,同步屏障为Handler消息机制增加了一种简单的优先级机制,异步消息的优先级要高于同步消息。
17. Handler在dispatchMessage时候会做哪些判断?
Message.callback (post) →
Callback.handleMessage (构造函数传递的 Callback) →
Handler.handleMessage (sendMessage) →
/**
* Handle system messages here.
*/
public void dispatchMessage(Message msg) {
if (msg.callback != null) {
handleCallback(msg);
} else {
if (mCallback != null) {
if (mCallback.handleMessage(msg)) {
return;
}
}
handleMessage(msg);
}
}
18. 在Activity中使用非静态Handler为什么会造成内存泄漏?
Looper → MessageQueue → Message → Handler → Activity
19. Message.obtain()方法是如何获取一个对象的?
链表对象池
20. MessageQueue内部数据结构是怎么样的?
链表结构
21. Looper类的中的loop()方法是一个死循环,为什么没有造成主线程阻塞?
主线程的死循环一直运行是不是特别消耗CPU资源呢? 其实不然,这里就涉及到Linux pipe/epoll机制,简单说就是在主线程的MessageQueue没有消息时,便阻塞在loop的queue.next()中的nativePollOnce()方法里,详情见Android消息机制1-Handler(Java层),此时主线程会释放CPU资源进入休眠状态,直到下个消息到达或者有事务发生,通过往pipe管道写端写入数据来唤醒主线程工作。这里采用的epoll机制,是一种IO多路复用机制,可以同时监控多个描述符,当某个描述符就绪(读或写就绪),则立刻通知相应程序进行读或写操作,本质同步I/O,即读写是阻塞的。 所以说,主线程大多数时候都是处于休眠状态,并不会消耗大量CPU资源。
22. HandlerThread的实现原理?
Handler + Thread
@Override
public void run() {
mTid = Process.myTid();
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
mTid = -1;
}
23. IntentService的实现原理?
HandlerThread + Service
@Override
public void onCreate() {
// TODO: It would be nice to have an option to hold a partial wakelock
// during processing, and to have a static startService(Context, Intent)
// method that would launch the service & hand off a wakelock.
super.onCreate();
HandlerThread thread = new HandlerThread("IntentService[" + mName + "]");
thread.start();
mServiceLooper = thread.getLooper();
mServiceHandler = new ServiceHandler(mServiceLooper);
}
只能处理Intent消息,处理完之后会停止自己。
private final class ServiceHandler extends Handler {
public ServiceHandler(Looper looper) {
super(looper);
}
@Override
public void handleMessage(Message msg) {
onHandleIntent((Intent)msg.obj);
stopSelf(msg.arg1);
}
}
24. AsyncTask的实现原理?
Handler + ThreadPool( SerialExecutor + THREAD_POOL_EXECUTOR)
- 核心线程:最少两个,最大四个
- 最大线程数: 2*CPU_COUNT + 1
- 线程闲置超时时间:30s
- 队列:LinkedBlockingQueue(128)
- 饱和策略:AbortPolicy(默认)
SerialExecutor:
private static class SerialExecutor implements Executor {
final ArrayDeque<Runnable> mTasks = new ArrayDeque<Runnable>();
Runnable mActive;
public synchronized void execute(final Runnable r) {
mTasks.offer(new Runnable() {
public void run() {
try {
r.run();
} finally {
scheduleNext();
}
}
});
if (mActive == null) {
scheduleNext();
}
}
protected synchronized void scheduleNext() {
if ((mActive = mTasks.poll()) != null) {
THREAD_POOL_EXECUTOR.execute(mActive);
}
}
}
THREAD_POOL_EXECUTOR:
static {
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(
CORE_POOL_SIZE, MAXIMUM_POOL_SIZE, KEEP_ALIVE_SECONDS, TimeUnit.SECONDS,
sPoolWorkQueue, sThreadFactory);
threadPoolExecutor.allowCoreThreadTimeOut(true);
THREAD_POOL_EXECUTOR = threadPoolExecutor;
}
24. 如何加载一个大图片?如何计算一张图片在内存中的大小?Gif加载的原理?
BitmapRegionDecoder
加载大图:
/**
* @param context 上下文对象
* @param bytes 图片的byte数据
* @param dstWidth 目标宽度
* @param dstHeight 目标高度
* @return 压缩后的bitmap
*/
public static final Bitmap compress(Context context, byte[] bytes,int dstWidth, int dstHeight) {
if(dstWidth < 0 || dstHeight < 0) return null;
Bitmap bitmap = null;
try {
BitmapFactory.Options opts = new BitmapFactory.Options();
opts.inJustDecodeBounds = true;//只获取图片的宽高
BitmapFactory.decodeByteArray(bytes, 0, bytes.length, opts);
int height = opts.outHeight;
int width = opts.outWidth;
int inSampleSize = 1;//压缩
if (width > height && width > dstWidth) {
inSampleSize = Math.round((float) width / (float) dstWidth);
} else if (height > width && height > dstHeight) {
inSampleSize = Math.round((float) height / (float) dstHeight);
}
if (inSampleSize <= 1)
inSampleSize = 1;
opts.inSampleSize = inSampleSize;
opts.inPreferredConfig = Bitmap.Config.ARGB_4444;//色彩模式
// bitmap可清除
opts.inPurgeable = true;
// bitmap可copy
opts.inInputShareable = true;
opts.inTargetDensity = context.getResources().getDisplayMetrics().densityDpi;
opts.inScaled = true;
opts.inTempStorage = new byte[16 * 1024];
opts.inJustDecodeBounds = false;
bitmap = BitmapFactory
.decodeByteArray(bytes, 0, bytes.length, opts);
} catch (ArrayIndexOutOfBoundsException e) {
e.printStackTrace();
} catch (OutOfMemoryError e) {
// 防止内存溢出导致程序崩溃而强制退出
e.printStackTrace();
}
return bitmap;
}
图片大小取决于色彩模式,色彩模式分为:
ARGB_8888:一个像素4个字节
ARGB_4444:一个像素2个字节 (已被抛弃)
RGB_565:一个像素2个字节
ALPHA_8:一个像素1个字节
图片大小计算:宽 x 高 x 色彩模式,比如一张480*1080大小的图片采用ARGB_8888色彩模式,在内存中的大小是:480*1080*4
25. drawable文件夹对应的的屏幕密度?
drawable文件夹对应着六种不同的屏幕密度,它们的对应关系如下:
- ldpi:低密度 (ldpi) 屏幕 (~120dpi)
- mdpi:中密度 (mdpi) 屏幕 (~160dpi)
- hdpi:高密度 (hdpi) 屏幕 (~240dpi)
- xhdpi:超高密度 (xhdpi) 屏幕 (~320dpi)
- xxhdpi:超超高密度 (xxhdpi) 屏幕 (~480dpi)
- xxxhdpi:超超超高密度 (xxxhdpi) 屏幕 (~640dpi)
因为png压缩会失真,可以制作.9.png的图片适配。另外,颜色或者图形图片可以用ShapeDrawable。
尺寸单位
- sp:文字
- dp:距离
如果要保证系统切换字体,应用程序的字体不变,使用dp。多种设备,线下计算好大小。
布局:
- 使用ConstraintLayout可以实现LinearLayout和RelativeLayout的功能
- 使用minWidth、minHeight、lines等属性
- 使用权重。
其它:
- TextView 字数限制
- ImageView scaleType 设置
- 根据屏幕宽高动态设置
26. LruCache的原理?
LruCache:最近最少使用算法。内部是用LinkedHashMap数据结构实现的,LinkedHashMap的构造函数有一个参数是accessOrder,这个参数表示的意思是:false 基于插入顺序;true 基于访问顺序 。在LruCache中参数accessOrder为true。
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}
另外,每次put一个元素的时候,就会检查下是否超过容器的大小,如果超过了,就会移除最老的那个元素,也就是LinkedHashMap的表头元素。
/**
* Caches {@code value} for {@code key}. The value is moved to the head of
* the queue.
*
* @return the previous value mapped by {@code key}.
*/
public final V put(@NonNull K key, @NonNull V value) {
if (key != null && value != null) {
Object previous;
synchronized(this) {
++this.putCount;
this.size += this.safeSizeOf(key, value);
previous = this.map.put(key, value);
if (previous != null) {
this.size -= this.safeSizeOf(key, previous);
}
}
if (previous != null) {
this.entryRemoved(false, key, previous, value);
}
this.trimToSize(this.maxSize);
return previous;
} else {
throw new NullPointerException("key == null || value == null");
}
}
/**
* Remove the eldest entries until the total of remaining entries is at or
* below the requested size.
*
* @param maxSize the maximum size of the cache before returning. May be -1
* to evict even 0-sized elements.
*/
public void trimToSize(int maxSize) {
while(true) {
Object key;
Object value;
synchronized(this) {
if (this.size < 0 || this.map.isEmpty() && this.size != 0) {
throw new IllegalStateException(this.getClass().getName() + ".sizeOf() is reporting inconsistent results!");
}
if (this.size <= maxSize || this.map.isEmpty()) {
return;
}
Entry<K, V> toEvict = (Entry)this.map.entrySet().iterator().next();
key = toEvict.getKey();
value = toEvict.getValue();
this.map.remove(key);
this.size -= this.safeSizeOf(key, value);
++this.evictionCount;
}
this.entryRemoved(true, key, value, (Object)null);
}
}
get 操作一次,也会将访问的结点移动到队尾。
LinkedHashMap 在put 或 get 的时候都会执行 afterNodeAccess 方法,这就让LinkedHashMap在可以将最新访问的结点移动到队尾。
27. FrameLayout,LinearLayout,RelativeLayout的性能对比?
FrameLayout > LinearLayout > RelativeLayout
LinearLayout 与 RelativeLayout:它们 layout 和 draw 过程所消耗的时间都差不多,差别在 measure 过程,RelativeLayout 的 measure 过程耗时 大于 LinearLayout 的 measure 过程。
原因:
- RelativeLayout:RelativeLayout会对子View做两次measure。首先RelativeLayout中子View的排列方式是基于彼此的依赖关系,而这个依赖关系可能和布局中View的顺序并不相同,在确定每个子View的位置的时候,就需要先给所有的子View排序一下。又因为RelativeLayout允许A,B 2个子View,横向上B依赖A,纵向上A依赖B。所以需要横向纵向分别进行一次排序测量。
- LinearLayout:如果子视图 lp.weight>0,会暂时先不测量这些子视图,在后面将把父视图剩余的高度按照weight值的大小平均分配给相应的子视图。
28. ViewStub,merge,include标签的区别?
- ViewStub:需要时才加载。
- merge:在 include 布局的根据和include到的父布局是一样的布局时,可以用merge标签来减少层级。
- include:抽取出相同的布局,避免重复创建布局,浪费资源。
29. 说说Window和WindowService的关系?
Window的添加过程:
Window(抽象类) → WindowManager(接口) → WindowManagerImpl → WindowManagerGlobal →
- mViews
- mRoots → setView → WindowSession → IWindowSession(Binder) → WindowManagerService
- mParams
- mDyingViews
Window的创建过程:
Activity → attach → PolicyManager → makeNewWindow → PhoneWindow Activity → onCreate → PhoneWindow → DecorView Activity → onResume → makeVisible → DecorView → VISIBLE
30. 如何做性能优化?
过度绘制:
- 去除必要的背景。例如:只使用应用程序的主题背景。
- 使布局扁平化。例如:使用ConstraintLayout,结合使用ViewStub, merge, include标签。
- 去除不必要的透明度,阴影等。
过度渲染:
- 交换缓冲区阶段,表示 CPU 等待 GPU 完成其工作的时间。 如果此竖条升高,则表示应用在 GPU 上执行太多工作。
- 命令问题阶段, 表示 Android 的 2D 渲染器向 OpenGL 发起绘制和重新绘制显示列表的命令所花的时间。 此竖条的高度与它执行每个显示列表所花的时间的总和成正比—显示列表越多,红色条就越高。 同步和上传阶段,表示将位图信息上传到 GPU 所花的时间。 大区段表示应用花费大量的时间加载大量图形。
- 绘制阶段,表示用于创建和更新视图显示列表的时间。 如果竖条的此部分很高,则表明这里可能有许多自定义视图绘制,或 onDraw 函数执行的工作很多。
- 测量/布局阶段,表示在视图层次结构中的 onLayout 和 onMeasure 回调上所花的时间。 大区段表示此视图层次结构正在花很长时间进行处理。 动画阶段,表示评估运行该帧的所有动画程序所花的时间。 如果此区段很大,则表示您的应用可能在使用性能欠佳的自定义动画程序,或因更新属性而导致一些意料之外的工作。
- 输入处理阶段,表示应用执行输入 Event 回调中的代码所花的时间。 如果此区段很大,则表示此应用花太多时间处理用户输入。 考虑将此处理任务分流到另一个线程。
- 其他时间/VSync 延迟阶段,表示应用执行两个连续帧之间的操作所花的时间。 它可能表示界面线程中进行的处理太多,而这些处理任务本可以分流到其他线程。
方法耗时:
- 相对执行时间长的方法,这种可以轻松找到,而且容易优化。在主线程中执行时间较长的方法,一定会影响页面每一帧的渲染速度。如果执行时间长的方法还在Activity,BroadcastReceiver,Service的生命周期中执行,那么就容易导致程序ANR。解决这种问题,就是把耗时的操作放到子线程中去执行。
- 执行时间短,但是执行频次很高的方法,因为执行次数多,累积效应下就会对性能产生很大的影响。解决这种问题,首先是避免递归调用,其次是优化方法实体操作,比如在自定义的View中,有时候onMeasure(),onLayout(),onDraw()方法会被调用多次,这时应该避免频繁的创建对象,能够定义为全局的变量就定义为全局变量。另外,比较两个float数值大小的执行时间是int数值的4倍左右;for循环的不同写法会对编译器优化这段代码会产生不同的效率等等。
内存优化:
- 内存泄漏(单例,静态对象等)
- 内存溢出(大对象,Bitmap等)
- 内存抖动(对象池,线程池等)
31. ART和Dalvik的区别?
- ART:在应用安装的时候就预编译字节码到机器语言。
- Dalvik:执行的是dex文件。
Android系统五层架构,从下往上依次是:
- Linux内核
- HAL
- 系统Native库和Android运行时环境
- Java框架层
- 应用层
Android系统启动过程是一个从下往上的过程:是由Boot Loader引导开机,依次进入 → Kernel → Native → Framework → App
… 具体启动过程查看标题链接文章
App层
- Zygote进程孵化出的第一个App进程是Launcher,这是用户看到的桌面App;
- Zygote进程还会创建Browser,Phone,Email等App进程,每个App至少运行在一个进程上。
- 所有的App进程都是由Zygote进程fork生成的。
应用程序启动
33.进程的生命周期?
1.缓存机制:
- 层级不同
- 缓存不同
2.局部刷新:
ListView和RecyclerView最大的区别在于数据源改变时的缓存的处理逻辑,ListView是”一锅端”,将所有的mActiveViews都移入了二级缓存mScrapViews,而RecyclerView则是更加灵活地对每个View修改标志位,区分是否重新bindView。
3.结论:
列表页展示界面,需要支持动画,或者频繁更新,局部刷新,建议使用RecyclerView,更加强大完善,易扩展;其它情况两者都OK,但ListView在使用上会更加方便,快捷。
35.APK 的打包过程?
- aapt 工具打包资源文件,生成 R.java 文件
- aidl 工具处理 AIDL 文件,生成对应的 .java 文件
- javac 工具编译 Java 文件,生成对应的 .class 文件
- 把 .class 文件转化成 Davik VM 支持的 .dex 文件
- apkbuilder 工具打包生成未签名的 .apk 文件
- jarsigner 对未签名 .apk 文件进行签名
- zipalign 工具对签名后的 .apk 文件进行对齐处理
zipalign 工具对签名后的 .apk 文件进行对齐处理的原因:目的是确保所有未压缩数据以相对于文件开头的特定对齐开始。具体来说,它会导致APK中的所有未压缩数据(如图像或原始文件)在4字节边界上对齐。对齐以后,系统就能更加快速的调用APP内的资源。
36.APK 的安装过程?
一个apk文件在安装到手机过程中,涉及到下面几个目录:
- system/app:系统自带的应用安装目录
- data/app:用户程序安装的目录,安装时把apk文件复制到此目录
- data/data:存放应用程序的数据
- data/dalvik-cache:将apk中的dex文件安装到dalvik-cache目录下
总体安装过程(用户程序):复制apk文件到data/app目录下,解压并扫描apk文件,解压后把dex文件(Dalvik字节码)保存到dalvik-cache目录,并在data/data目录下创建对应的应用数据目录。(然后PMS解析AndroidManifest.xml文件,读取程序的应用包名、APK的安装位置、版本、userID、权限等信息, 并存储到data/system/packages.xml文件中,最后Launcher应用程序从PMS读取程序,显示在桌面上。)
可以仔细看看上面这篇文章。
37. APK 为什么要签名?是否了解过具体的签名机制?
Android 为了确认 apk 开发者身份和防止内容的篡改,设计了一套 apk 签名的方案保证 apk 的安全性,即在打包时由开发者进行 apk 的签名,在安装 apk 时Android 系统会有相应的开发者身份和内容正确性的验证,只有验证通过才可以安装 apk,签名过程和验证的设计就是基于非对称加密的思想。
- Android 在 7.0 以前使用的一套签名方案:在 apk 根目录下的 META-INF/ 文件夹下生成签名文件,然后在安装时在系统的
PackageManagerService里进行签名文件的验证。 - 从 7.0 开始,Android 提供了新的 V2 签名方案:利用 apk(zip) 压缩文件的格式,在几个原始内容区之外增加了一块用于存放签名信息的数据区,然后同样在安装时在系统的
PackageManagerService里进行 V2 版本的签名验证,V2 方案会更安全、使校验更快安装更快。
当然 V2 签名方案会向后兼容,如果没有使用 V2 签名就会默认走 V1 签名方案的验证过程。
38. Rx Java
39.ANR的原因,如何分析?
原因:
ANR:程序未响应。在主线程中,一定时间内没有完成某个事件就会触发ANR。它的触发机制是在处理某个事件前,发送一个延时消息,如果在规定时间内完成了这个事件处理,就移出这个延时消息。否则,这个延时消息就会执行,从而触发ANR。
触发ANR的场景大概有:
- Service Timeout:Service在特定的时间内无法处理完成
- BroadcastQueue Timeout:BroadcastReceiver在特定时间内无法处理完成
- ContentProvider Timeout:内容提供者执行超时
- inputDispatching Timeout:按键或触摸事件在特定时间内无响应。
| 场景 | 事件 | 时间 |
|---|---|---|
| Service | SERVICE_TIMEOUT | 20s |
| Service | SERVICE_BACKGROUND_TIMEOUT | 200s |
| BroadcastQueue | BROADCAST_FG_TIMEOUT | 10s |
| BroadcastQueue | BROADCAST_BG_TIMEOUT | 60s |
| ContentProvider | CONTENT_PROVIDER_PUBLISH_TIMEOUT | 10s |
| inputDispatching | KEY_DISPATCHING_TIMEOUT | 5s |
| processStart | PROC_START_TIMEOUT_MSG | 10s |
在AMS中触发时, 会顺序依次执行:
- 输出ANR Reason信息到EventLog. 也就是说ANR触发的时间点最接近的就是EventLog中输出的am_anr信息;
- 收集并输出重要进程列表中的各个线程的traces信息,该方法较耗时;
- 输出当前各个进程的CPU使用情况以及CPU负载情况;
- 将traces文件和 CPU使用情况信息保存到dropbox,即data/system/dropbox目录
- 根据进程类型,来决定直接后台杀掉,还是弹框告知用户
分析:
获取ANR文件:data/anr/ ,如果 adb pull 没有权限,就是用 adb bugreport,使用 AndroidStudio → Analyze → Analyze Stack Trace 导入文件。
对于service、broadcast、provider、input发生ANR后,中控系统会马上去抓取现场的信息,用于调试分析。收集的信息包括如下:
将am_anr信息输出到EventLog,也就是说ANR触发的时间点最接近的就是EventLog中输出的am_anr信息。
收集以下重要进程的各个线程调用栈trace信息,保存在data/anr/traces.txt文件:当前发生ANR的进程,system_server进程以及所有persistent进程;audioserver, cameraserver, mediaserver, surfaceflinger等重要的native进程;CPU使用率排名前5的进程。
将发生ANR的reason以及CPU使用情况信息输出到main log。
将traces文件和CPU使用情况信息保存到dropbox,即data/system/dropbox目录。
对用户可感知的进程则弹出ANR对话框告知用户,对用户不可感知的进程发生ANR则直接杀掉。
整个ANR信息收集过程比较耗时,其中抓取进程的trace信息,每抓取一个等待200ms,可见persistent越多,等待时间越长。关于抓取trace命令,对于Java进程可通过在adb shell环境下执行kill -3 [pid]可抓取相应pid的调用栈;对于Native进程在adb shell环境下执行debuggerd -b [pid]可抓取相应pid的调用栈。对于ANR问题发生后的蛛丝马迹(trace)在traces.txt和dropbox目录中保存记录。更多细节详见理解Android ANR的信息收集过程,http://gityuan.com/2016/12/02/app-not-response。
有了现场信息,可以调试分析,先定位发生ANR时间点,然后查看trace信息,接着分析是否有耗时的message、binder调用,锁的竞争,CPU资源的抢占,以及结合具体场景的上下文来分析,调试手段就需要针对前面说到的message、binder、锁等资源从系统角度细化更多debug信息,这里不再展开,后续再以ANR案例来讲解。
作为应用开发者应让主线程尽量只做UI相关的操作,避免耗时操作,比如过度复杂的UI绘制,网络操作,文件IO操作;避免主线程跟工作线程发生锁的竞争,减少系统耗时binder的调用,谨慎使用sharePreference,注意主线程执行provider query操作。简而言之,尽可能减少主线程的负载,让其空闲待命,以期可随时响应用户的操作。
解决方法:
主线程中耗时的操作都放到子线程中去。
40.如何分析Crash? crash 分类:
- Framework Crash
- Kernel Crash
- Native Crash:Native crash的工作核心是由debuggerd守护进程来完成
Framework Crash:
- 对于system_server进程:文章Android系统启动-SystemServer上篇,system_server启动过程中由RuntimeInit.java的commonInit方法设置UncaughtHandler,用于处理未捕获异常;
- 对于普通应用进程:文章理解Android进程创建流程 ,进程创建过程中,同样会调用RuntimeInit.java的commonInit方法设置UncaughtHandler。
通过RuntimeInit.java的commonInit方法设置UncaughtHandler。
流程总概况:
- 首先发生crash所在进程,在创建之初便准备好了defaultUncaughtHandler,用来来处理Uncaught Exception,并输出当前crash基本信息;
- 调用当前进程中的AMP.handleApplicationCrash;经过binder ipc机制,传递到system_server进程;
- 接下来,进入system_server进程,调用binder服务端执行AMS.handleApplicationCrash;
- 从mProcessNames查找到目标进程的ProcessRecord对象;并将进程crash信息输出到目录/data/system/dropbox;
- 执行makeAppCrashingLocked:创建当前用户下的crash应用的error receiver,并忽略当前应用的广播;停止当前进程中所有activity中的WMS的冻结屏幕消息,并执行相关一些屏幕相关操作;
- 再执行handleAppCrashLocked方法:当1分钟内同一进程连续crash两次时,且非persistent进程,则直接结束该应用所有activity,并杀死该进程以及同一个进程组下的所有进程。然后再恢复栈顶第一个非finishing状态的activity;当1分钟内同一进程连续crash两次时,且persistent进程,,则只执行恢复栈顶第一个非finishing状态的activity;当1分钟内同一进程未发生连续crash两次时,则执行结束栈顶正在运行activity的流程;
- 通过mUiHandler发送消息SHOW_ERROR_MSG,弹出crash对话框;
- 到此,system_server进程执行完成。回到crash进程开始执行杀掉当前进程的操作;
- 当crash进程被杀,通过binder死亡通知,告知system_server进程来执行appDiedLocked();
- 最后,执行清理应用相关的activity/service/ContentProvider/receiver组件信息。
Native程序通过link连接后,当发生Native Crash时,则kernel会发送相应的signal,当进程捕获致命的signal,通知debuggerd调用ptrace来获取有价值的信息(这是发生在crash前)。
- kernel 发送signal给target进程(包含native代码);
- target进程通过debuggerd_signal_handler,捕获signal:建立于debuggerd进程的socket通道;将action = DEBUGGER_ACTION_CRASH的消息发送给debuggerd服务端;阻塞等待debuggerd服务端的回应数据。
- debuggerd作为守护进程,一直在等待socket client的连接,此时收到action = DEBUGGER_ACTION_CRASH的消息;
- 执行到handle_request时,通过fork创建子进程来执行各种dump相关操作;
- 新创建的进程,通过socket与system_server进程中的NativeCrashListener线程建立socket通道,并向其发送native crash信息;
- NativeCrashListener线程通过创建新的名为“NativeCrashReport”的子线程来执行AMS的handleApplicationCrashInner方法。
41.SparseArray 和 ArrayMap?
Java虚拟机
1.Java内存区域?
- 程序计数器:当前执行的代码的信号指示器。线程私有。
- Java虚拟机栈:每执行一个方法的时候,就会创建一个栈帧,用于存储局部变量表(基本数据类型,对象引用,returnAdress类型),操作数栈,动态链接,方法出口等。线程私有。
- 本地方法栈:与Java虚拟机类似,只不过是为本地方法服务的。线程私有。
- 堆:存储对象和数组。线程共享。
- 方法区(非堆区):存储虚拟机加载的类信息,常量,静态变量,以及即时编译器编译后的代码等数据。线程共享。
- 运行常量池:用于存储编译时期生成的字面量和符号引用。
2.对象创建过程?
- 检查new 指令,根据这个new 指令的参数,能否在常量池中找到一个类的符号引用,并且这个符号引用的类是否被加载,解析和初始化过。如果没有,那必须先执行类的加载过程。
- 为新生对象分配必要的内存(内存是绝对完整的,指针碰撞;内存并不是完整的,空前列表)。
- 对对象进行必要的设置(对象的内存布局)。
对象的内存布局:
- 对象头:存储对象自身的运行时数据:哈希码、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳等;类型指针:对象指向它的类的元数据的指针,虚拟机通过这个指针来确定这个对象属于哪个类的实例。
- 实例数据:在程序代码中所定义的各种类型的字段内容。
- 对齐填充:(并不是必要存在的)占位符。
3.对象已死吗?
- 引用计数法:给对象添加一个引用计数器,每当有一个地方引用它,计数器值就加1;当引用失效时,计数器就减1;任何时刻计数器为0的对象就是不可能再被使用的。相互引用,引用计数都不为0,不能被垃圾回收器回收。
- 可达性分析算法:当一个对象到GC Roots 没有任何引用链相连时,就证明 这个对象是不可用的。
4.在Java语言中可作为GC Roots的对象包括几种?
- Java虚拟机栈中引用的对象
- 方法区中类静态属性引用的对象。
- 方法区中类常量引用的对象。
- 本地方法栈中JNI引用的对象。
5.引用?
- 强引用:只要强引用还存在,垃圾收集器永远不会回收掉被引用的对象。
- 软引用:并非必需对象,在系统将要发生内存溢出异常之前,将会把这些对象列入回收范围之中进行第二次回收。
- 弱引用:非必需对象,被弱引用关联的对象只能生存到下一次垃圾收集之前。
- 虚引用:无法通过虚引用来取得一个对象实例。
5.生存还是死亡 :两次标记?
两次标记:
- 判断对象到GC Roots是否有引用链相连接。
- 判断有没有必要执行对象的finalize()方法。如果有,就会放到一个F-Queue队列中,稍后由一个虚拟机自建的、低优先级的Finalizer 线程去执行它。稍后,GC将对F-Queue中的对象进行第二次标记。P66
6.回收方法区:废弃常量和无用的类。
无用的类:
- 该类的所有实例都已经被回收。
- 加载该类的ClassLoader已经被回收。
- 该类对应的java.lang.Class对象没有在任何地方被引用,无法在任何地方通过反射访问该类方法。
7.垃圾回收算法
- 标记清除:首先标记出所有需要回收的对象,在标记完之后统一回收所有被标记的对象。主要有两个不足:一个是效率问题,标记和清除两个过程的效率不高;另一个是空间问题,标记清除之后会产生大量连续的内存碎片,空间碎片太多可能会导致以后在程序运行中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发一次垃圾回收动作。
- 复制算法:将可用内存按照容量划分为大小相等的两块,每次只使用其中的一块。当这一块内存用完了,就将还存活着的对象复制到另一块上面,然后再把已使用的内存空间一次清理掉。
- 标记整理: 让所有还存活的对象都向一端移动,然后直接清理掉端边界以外的内存。
- 分代收集:新生代(复制算法),老年代(标记-清除和标记-整理)。
8.Dalvik 有两种基本的 GC 模式?
GC_CONCURRENT 和 GC_FOR_ALLOC:
- GC_CONCURRENT 对于每次收集将阻塞主线程大约 5ms 。因为每个操作都比一帧(16ms)要小,GC_CONCURRENT 通常不会造成你的应用丢帧。
- GC_FOR_ALLOC 是一种 stop-the-world 收集,可能会阻塞主线程达到 125ms 以上。GC_FOR_ALLOC 几乎每次都会造成你的应用丢失多个帧,导致视觉卡顿,特别是在滑动的时候。
9.Minor GC和Major GC的区别??
- Minor GC(新生代GC):指发生在新生代的垃圾回收动作。Java大多数对象具有朝生夕死的特性,所以新生代GC非常频繁,一般回收速度也比较快。
- Major GC(老年代GC):指发生在老年代的垃圾回收动作。出现一个Major GC至少伴随着一次Minor GC。Major GC至少比Minor GC慢10倍以上。
10.类的加载时机?
加载,验证,解析,准备,初始化,使用,卸载
加载:
- 通过一个类的全名限定符来获取定义此类的二进制字节流。
- 将字节流代表的静态存储结构转化为方法区的运行时结构。
- 在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的访问接口。
初始化:
- 遇到new,gestatic,putstatic,invoke static指令。
- 使用java.lang.reflect包的方法对类进行反射调用的时候,如果类没有初始化,既需要先触发初始化。
- 当初始化一个类的时候,如果发现其父类没有进行初始化,则需要先触发其父类的初始化。
- 当虚拟机启动的时候,用户需要指定一个要执行的主类,虚拟机会先初始化这个类。
11.双亲委派模型?
从虚拟机来看:
- 启动类加载器,虚拟机的一部分,由C++实现
- 其它所有类的加载器,不是虚拟机的一部分,由Java实现
从开发人员来看:
- 启动类加载器
- 扩展类加载器
- 应用程序类加载器
双亲委派模型的工作过程:如果一个类加载器收到了加载类的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求都应该传送到顶层的启动类加载器中,只有父类加载器反馈自己无法完成这个加载请求(它的搜素范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
12.Java的垃圾回收机制?
- 对象已死吗?
- 生存还是死亡?
- 垃圾回收算法
13.JVM中内存分配机制?
- 对象优先在新生代Eden分配
- 大对象(很长的字符串和数组)直接进入老年代
- 长期存活的对象将进入老年代
- 动态对象年龄判断:对象年龄计数器(15)
- 空间分配担保
14.什么时候会触发GC?
- 当Eden区没有足够的空间进行分配时,虚拟机将发起一次Minor GC。
- 分配大对象导致内存还有空间时会提前触发GC来为大对象分配内存。
- 在发生Minor GC 之前,虚拟机会先检查老年代最可用的连续空间是否大于新生代所有对象总空间,如果这个条件成立, 那么Minor GC 可以确保是安全的。如果不成立,则虚拟机会查看 HandlePromotionFailure 设置值是否允许担保失败。如果允许,那么会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试进行一次Minor GC。如果小于,或者 HandlePromotionFailure 设置不允许冒险,那这时也要改为进行一个 Full GC。(当新生代晋升为老年代时,老年代最大可用的连续空间大于历次晋升到老年代对象的平均大小,触发Minor GC,如果小于,或者 HandlePromotionFailure 设置不允许冒险,那这时也要改为进行一个 Full GC。)
设计模式
考察设计模式知识时,一般只会问你熟悉的设计模式,会要求写代码。另外,与设计模式相关的,还会问到面向对象原则。
1.面向对象六大原则
- 开闭原则:类应该对扩展开发,对修改关闭。
- 依赖倒置原则:要依赖于抽象,不要依赖于具体类。
- 单一责任原则:一个类应该只有一个引起变化的原因。
- 里氏替换原则:子类可以扩展父类的功能,但不能改变父类原有的功能。
- 接口隔离原则:不应该被迫地依赖那些根本用不到的方法。
- 迪米特原则:一个对象应该对其它对象保持最少的了解。
2.面向对象思想
- 封装:让变量和访问这个变量的方法放在一起,将一个类的成员变量全部定义成私有的,只有这个类自己的方法才可以访问这些成员变量。
- 继承:子类自动的共享父类数据和方法,并可以加入新的内容,提高了重用性和可扩展性。
- 抽象:找出一些事物的相似之处,然后将这些事物归为一个类,这个类只考虑这些事物的相似之处,并且忽略当前主题和目标无关的方面。
- 多态:继承、覆盖、将父类引用指向子类。
3.常用设计模式
- 策略模式:定义了算法簇,分别封装起来,让它们之间可以互相替换,此模式让算法的变化独立于使用算法的用户。
- 观察者模式:定义了对象之间一对多的依赖,这样一来,当一个对象改变状态时,它的所有依赖者都会收到通知并自动更新。
- 装饰着模式:动态地将责任添加到对象上。若要扩展功能,装饰着提供了比继承更有弹性的替代方案。
- 工厂方法模式:定义了一个创建对象的接口,但由子类决定要实例化的类是哪一个。工厂方法把类的实例化延迟到子类。
- 抽象工厂模式:提供一个接口,用于创建相关或依赖对象的家族,而不需要明确指定具体类。
- 单例模式:确保一个类只有一个实例,并提供一个全局的访问点。(懒汉式,饿汉式,静态内部类,枚举)
//双重检验
class Singleton{
private static volatile Singleton INSTANCE;
private Singleton(){}
public static getInstance(){
if(INSTANCE == null){//避免不必要的锁,因为锁耗费性能
synchronized(Singleton.class){//防止多线程
if(INSTANCE == null){//前面一个线程锁释放,后面一个线程进来了
INSTANCE = new Singleton();
}
}
}
return INSTANCE;
}
}
- 模版方法模式:在一个方法中定义一个算法的骨架,而将一些步骤延迟到子类中。模版方法使得子类可以在不改变算法的结构下,重新定义算法的步骤。
- 状态模式:允许对象在内部状态改变时改变它的行为,对象看起来好像修改了它的类。
- 适配器模式:将一个类的接口,转换成客户期望的另一个接口,适配器让原本接口不兼容的类可以合作无间。
- 外观模式:提供了一个统一的接口,用来访问子系统的一群接口。外观模式定义了一个高层接口,让子系统更容易使用。
- 代理模式:为另外一个对象提供一个替身或占位符以控制对这个对象的访问。
计算机网络
考察计算机网络知识时,一般只倾向于问一些Android会用到的网络知识。
1. HTTP协议的连接过程?
- 分析链接指向页面的URL
- 向DNS请求解析IP地址
- 域名系统解析出IP地址
- 客户端与服务器建立TCP连接
- 客户端发出取文件命令
- 服务器做出响应,把文件发送给浏览器
- 释放TCP连接
客户端显示请求文件的文本
2. HTTP协议的状态码206,301,302,304,403,404,500的含义?
状态码:
- 1xx:表示通知消息,如:请求收到了或正在进行处理。
- 2xx:表示成功,如:接受或知道。
- 3xx:表示重定向,如:要完成请求还需要采取进一步的行动。
- 4xx:表示客户端的差错,如:请求中有错误的语法或不能完成。
- 5xx:表示服务端的差错,如:服务器失效无法完成请求。
- 206:表示只需要目标URL上的部分资源
- 301:表示永久重定向
- 302:表示重定向(转发)
- 304:表示服务器告诉客户端读取本地缓存
- 400:错误的请求
- 403:表示客户端没有权限
- 404:表示客户端异常
- 416:客户端请求的范围无效(断点下载)
- 500:表示服务端异常
3. HTTP协议如何实现断点上传和断点下载?
- 响应码206:Partial Content
- 响应码416:Range Not Satisfiable
- 请求头:Range (请求的数据范围)
- 响应头:Content-Range(响应的数据范围)
- RandomAccessFile
4. HTTP协议的请求头中哪些代表取缓存?
Last-Modified和If-Modified-Since:
- 响应头Last-Modified: 标记文件在服务器最后被修改的时间。
- 请求头If-Modified-Since: 询问服务器该时间后文件是否被修改过。
Etag主要是问了解决Last-Modified无法解决的一些问题:
- 一些文件周期性的更改,但是它的内容并不改变;这时候并不希望客户端认为文件被修改过。
- 某些文件修改非常频繁,比如在秒以下的时间内修改,If-Modified-Since能检查到的粒度是S级的,这种无法判断。
Etag和If-None-Match:
- 响应头Etag: 存放服务器生成的一个序列值。
- 请求头If-None-Match: 询问服务器该文件是否被修改过。
HTTP 补充
请求方式:
| 方式 | 意义 |
|---|---|
| OPTIONS | 请求一些选项信息 |
| GET | 请求读取由URL所标志的信息 |
| HEAD | 请求读取由URL所标志的信息的首部 |
| POST | 给服务器添加信息 |
| PUT | 在指明的URL下存储一个文档 |
| DELETE | 删除指明的URL所标记的资源 |
| TRACE | 用来进行环回测试的报文 |
| CONNECT | 用于代理服务器 |
5. HTTPS的SSL层的功能和工作原理?
SSL的功能:
- SSL 服务器鉴别:允许用户证实服务器的身份。
- 加密的SSL会话:客户端和服务器交互的所有数据都在发送方解密,在接受方解密。SSL还提供了一种检测信息是否被攻击者篡改的机制。
- SSL 客户端鉴别:允许服务器证实客户的身份。
SSL的工作原理:
老的版本:
- 浏览器向服务器发送浏览器的SSL版本号和密码编码的参数选择。
- 服务器向浏览器发送服务器的SSL版本号、密码编码的参数选择及服务器的证书。证书包括服务器的公钥。此证书是由某个认证中心用自己的密钥加密,然后发送给服务器。
- 浏览器有一个可信的CA表,表中有每一个CA的公钥。当浏览器收到服务器发来的证书时,就检查此证书的发行者是否在自己的可信的CA表中。如不在,则后面的加密和鉴别连接就不能继续下去。如在,浏览器就使用CA相应公钥对证书解密,这样就得到了服务器的公钥。
- 浏览器随机的产生一个对称会话密钥,并用服务器的公钥加密,然后将加密的会话密钥发送给服务器。
- 浏览器向服务器发送一个报文,说明浏览器以后使用此会话密钥进行加密。然后浏览器再向服务器发送一个单独的加密报文,指出浏览器端的握手过程已经完成。
- 服务器向浏览器发送一个报文,说明服务器以后使用此会话密钥进行加密,然后服务器再向浏览器发送一个单独的加密报文,指出服务端的握手过程已经完成。
- SSL的握手过程至此已经完成,下面就开始SSL的会话过程。浏览器和服务器都使用这个会话密钥对所发送的报文进行加密。
新的版本(TLS 1.2 + RSA ):
- 协商加密算法:客户端向服务端发送TLS版本号和一些可选的加密算法;服务端从中选定自己支持的算法并(如RSA)并告知客户端。
- 服务端鉴别:服务端向客户端发送包含其RSA公钥的数字证书;客户端使用该证书的认证机构CA公开发布的RSA公钥对该证书进行验证。
- 会话密钥计算:客户端随机产生一个秘密数;用服务端的RSA公钥进行加密后发送给服务端;双方根据协商的算法产生共享的对称会话密钥。
- 安全数字传输:双方用会话密钥加密和解密它们之间传送的数据并验证其完整性。
更安全、更现代的方式是:TLS 1.2/1.3 + ECDHE 密钥交换
建议在实践和设计中优先使用 TLS 1.3 或 TLS_ECDHE_ 开头的加密套件
6. TCP协议与UDP协议的区别?
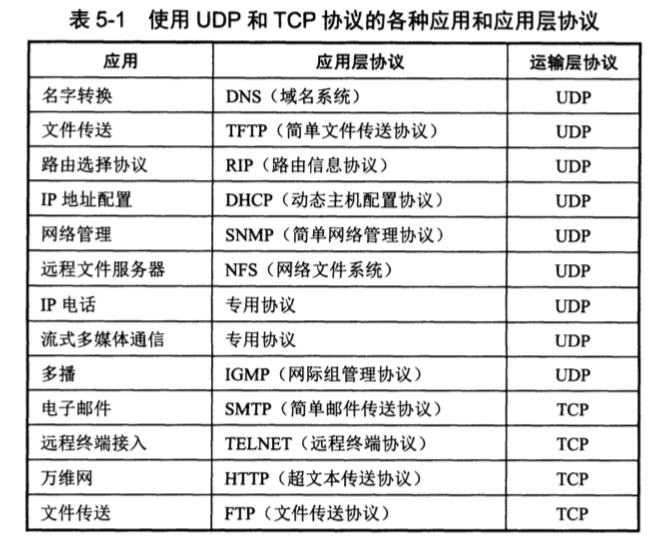 协议端口号:协议栈层间的抽象的协议端口是软件端口。软件端口:是应用层的各种协议进程与运输实体进行层交互的一种地址。
协议端口号:协议栈层间的抽象的协议端口是软件端口。软件端口:是应用层的各种协议进程与运输实体进行层交互的一种地址。
TCP/IP 的运输层用一个16位端口号来标志一个端口。端口号只具有本地意义,它只是为了标志计算机应用层中的各个进程在和运输层交互时的层间接口。
两个计算机中的进程要互相通行:IP地址+端口号
服务端使用的端口号:熟知端口号和系统端口号
常用的熟知端口号:
| 应用协议 | 端口号 | 描述 |
|---|---|---|
| FTP | 21 | 文件传输协议(控制连接) |
| TELNET | 23 | 远程登录 |
| SMTP | 25 | 简单邮件传输协议 |
| DNS | 53 | 域名解析(UDP/TCP) |
| TFTP | 69 | 简单文件传输协议(基于UDP) |
| HTTP | 80 | 超文本传输协议 |
| SNMP | 161 | 简单网络管理协议(管理) |
| SNMP Trap | 162 | SNMP陷阱信息(代理通知管理器) |
| HTTPS | 443 | 加密的 HTTP(安全传输) |
登记端口号:数值为1024~49151。必须在IANA按照规定的手续登记,以防止重复。
客户端使用的端口号:数值为49152~65535。由于这类端口号仅在客户端进程运行时才动态选择,因此又叫做短暂端口号。
UDP:
- UDP是无连接的。
- UDP使用尽最大努力交付。
- UDP是面向报文的。
- UDP没有拥塞控制(很多实用应用、IP电话、实时视频会议)
- UDP支持一对一、一对多、多对一和多对多的交互通信。
- UDP的首部(源端口,目的端口,长度和检验和)开销小,只有8个字节,比TCP的20个字节的首部要短。
TCP:
- TCP是面向连接的运输层协议。
- 每一条TCP连接只能有两个端点(端点:套接字或插口,端口号拼接到IP地址即套接字)。
- TCP提供可靠交付的服务,也就是说,通过TCP连接传递的数据,无差错、不丢失、不重复、并且按序到达。
- TCP提供全双工通信(发送缓存和接受缓存)。
- 面向字节流(流是指流入到进程或从进程流出的字节序列)
TCP 流量控制和拥塞控制:
- 流量控制:让发送方的发送速率不要太快,要让接收方来得及接收。(利于滑动窗口机制可以很方便的地在TCP连接上实现对发送方的流量控制)
- 拥塞控制:防止过多的数据注入到网络中,这样可以使网络中的路由器或链路不至于过载。
拥塞控制的方法:慢开始,拥塞避免,快重传和快恢复。
- 慢开始:当主机开始发送数据时,由于不清楚网络的负荷情况,所以如果立即把大量数据字节注入网络,那么就很可能引起网络拥塞。经验证明,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是说,由小到大逐渐增大拥塞窗口控制。
P232
7. TCP协议的三次握手和四次挥手?
ACK:确认值(Acknowledgement),为1便是确认连接。 ack:确认编号(Acknowledgement Number),即接收到的上一次远端主机传来的seq然后+1,再发送给远端主机。提示远端主机已经成功接收上一次所有数据。
TCP连接: 图5-31画出了TCP的建立的连接过程。假定主机A运行的TCP客户程序,而B运行TCP服务程序。最初两端的TCP进程都处于CLOSED(关闭)状态。图中在主机下面的方框分别是TCP进程中所处的状态。请注意,A主动打开连接,而B被动打开连接。

B的TCP服务器进程先创建传输控制模块TCB,准备接受客户进程的连接请求。然后服务进程就处于LISTEN(收听)状态,等待客户的连接请求。如有,即做出响应。
A的TCP客户进程也是先创建传输控制模块TCB,然后向B发出连接请求报文段,这是首部中的同步位SYN(Synchronize Sequence Numbers:同步序列编号)=1,同时选择一个初始序号seq=x。TCP规定,SYN报文段(即SYN=1的报文段)不能携带数据,但要消耗一个序号。这时,TCP客户进程进入SYN-SENT(同步已发送)状态。
B收到连接请求报文段之后,如同意连接,则向A发送确认。在确认报文段中应把SYN位和ACK(Acknowledge character:确认字符)位都置1,确认号ack=x+1,同时也为自己选择一个初始序号seq=y。请注意,这个报文段也不能携带数据,但同样要消耗一个序号。这时TCP服务器进程进入SYN-RCVD(同步收到)状态。
TCP客户进程收到B的确认后,还要向B给出确认。确认报文段的ACK置1,确认号ack=y+1,而自己的序号seq=x+1。TCP的标准规定,ACK报文段可以携带数据,但如果不携带数据则不消耗序号,在这种情况下,下一个数据报文段的序号,仍是seq=x+1。这时,TCP连接已经建立,A进入ESTABLISHED(已建立连接状态)。
B收到A的确认后,也进入ESTABLISHED状态。 
8. TCP协议为什么有三次握手和四次挥手?
为什么有三次握手:主要是为了防止已失效的连接请求报文段突然又传送到了服务端,而产生错误。
为什么客户端在TIME_WAIT状态必须等待2MSL的时间:
- 为了保证客户端发送的最后一个ACK报文段能够到达服务端。
- 防止“已失效的连接请求报文段“出现在本连接中。
9. OSI的体系结构?TCP/IP的体系结构?五层协议的体系结构?
体系结构(实际应用中采用的是TCP/IP体系结构):
- OSI的体系结构:应用层,表示层,会话层,运输层,网络层,数据链路层,物理层。
- TCP/IP的体系结构:应用层,运输层,网际层IP,网络接口层(解决不同网络的互连问题)。
- 五层协议的体系结构:应用层,运输层,网络层,数据链路层,物理层。
10. 五层协议的体系结构每一层的作用?
- 应用层:通过应用进程间的交互来完成特定网络应用。我们把应用层交互的数据单元称为报文。(域名系统DNS,HTTP协议,电子邮件的SMTP协议)
- 传输层:负责向两台主机中进程之间的通信提供通用的数据传输服务(TCP报文段,UDP用户数据报)。(TCP协议,UDP协议)
- 网络层:1.负责为分组交换网上的不同主机提供通信服务。在发送数据时,网络层把运输层产生的报文段或用户数据数据报封装成分组或包进行传送。2.选择合适的路由,使源主机运输层所传下来的分组,能够通过网络中的路由器找到主机。
- 数据链路层:将网络层传下来的数据报组装成帧,在两个相邻的结点间的链路上传送帧。
- 物理层:在物理层上所传数据的单位是比特。发送方发送1(或0)时,接收方应收到1(或0)。
11.HTTP 1.0 1.1 2.0的区别?
HTTP 1.0 与HTTP 1.1的区别:
- 长连接
- 节约带宽
- HOST域
HTTP 1.1 与HTTP 2.0的区别:
- 多路复用:多个请求共用一个 TCP 连接,并行传输。
- 二进制分帧
- 首部压缩:减少重复传输的 HTTP 头。
- 服务器推送:服务端可主动推送资源(CSS/JS)。
假设一个 HTTP/2 请求包含两个部分:请求的 URL 和请求的头部数据。在 HTTP/1.1 中,整个请求会作为一个大的 HTTP 消息发送。但在 HTTP/2 中,这个请求会被分解为两个二进制帧:
- 一个头部帧,包含请求的头部(如 URL、User-Agent)。
- 一个数据帧,包含请求体的内容。
每个帧都会有一个标识符和一些额外的信息,指示它们属于同一个请求,或者哪个部分属于哪个数据。服务器会接收这些帧并重组成一个完整的 HTTP 请求。
12.什么是CDN?
CDN(Content Delivery Network ):内容分发网络。其目的是通过在现有的Internet中增加一层新的网络架构,将网络的内容发布到最近用户的网络“边缘“,使用户就近取得所需的网络,解决Internet网络拥塞状况,提高用户访问网络的响应速度。从技术上解决由于网络带宽小,用户访问量大,网络分布不均等原因,解决用户访问网络的响应速度慢的根本原因。
13.两类密码体制?
- 对称密钥密码体制:加密密钥与解密密钥是相同的密码体制(AES,DES等)
- 公钥密码体制:公钥密码体制使用不同的加密密钥与解密密钥(RSA)
其它加密方式:MD5,Base64(Base64就是一种基于64个可打印字符来表示二进制数据的方法)等。
连接服务器优化策略:
- 不用域名,用 IP 直连:首次域名解析一般需要几百毫秒,可通过直接向 IP 而非域名请求,节省掉这部分时间,同时可以预防域名劫持等带来的风险。当然为了安全和扩展考虑,这个 IP 可能是一个动态更新的 IP 列表,并在 IP 不可用情况下通过域名访问。
- 服务器合理部署:服务器多运营商多地部署,一般至少含三大运营商、南中北三地部署。配合上面说到的动态 IP 列表,支持优先级,每次根据地域、网络类型等选择最优的服务器 IP 进行连接。对于服务器端还可以调优服务器的 TCP 拥塞窗口大小、重传超时时间(RTO)、最大传输单元(MTU)等。
传输数据优化策略:
- 连接复用:节省连接建立时间,如开启 keep-alive。
- 请求合并:即将多个请求合并为一个进行请求,比较常见的就是网页中的 CSS Image Sprites。 如果某个页面内请求过多,也可以考虑做一定的请求合并。
- 减小请求数据大小:(1) 对于 POST 请求,Body 可以做 Gzip 压缩,如日志;(2) 对请求头进行压缩,这个 Http 1.1 不支持,SPDY 及 Http 2.0 支持。 Http 1.1 可以通过服务端对前一个请求的请求头进行缓存,后面相同请求头用 md5 之类的 id 来表示即可。
- CDN 缓存静态资源:缓存常见的图片、JS、CSS 等静态资源。
- 减小返回数据大小:(1) 压缩,一般 API 数据使用 Gzip 压缩;(2) 精简数据格式,如 JSON 代替 XML,WebP 代替其他图片格式。(3) 对于不同的设备不同网络返回不同的内容,如不同分辨率图片大小。(4) 增量更新,需要数据更新时,可考虑增量更新。如常见的服务端进行 bsdiff,客户端进行 bspatch。(5) 大文件下载,支持断点续传,并缓存 Http Resonse 的 ETag 标识,下次请求时带上,从而确定是否数据改变过,未改变则直接返回 304。
- 数据缓存:缓存获取到的数据,在一定的有效时间内再次请求可以直接从缓存读取数据。
其他优化手段:
- 预取:包括预连接、预取数据。
- 分优先级、延迟部分请求:将不重要的请求延迟,这样既可以削峰减少并发、又可以和后面类似的请求做合并。
- 多连接:对于较大文件,如大图片、文件下载可考虑多连接。 需要控制请求的最大并发量,毕竟移动端网络受限。
监控:
优化需要通过数据对比才能看出效果,所以监控系统必不可少,通过前后端的数据监控确定调优效果。
15.DNS解析过程
- 查询 浏览器、操作系统(客户端) 缓存
- 请求本地域名服务器
- 本地域名服务器未命中缓存,其请求根域名服务器。
- 根域名服务器返回所查询域的主域名服务器。(主域名、顶级域名,如com、cn)
- 本地域名服务器请求主域名服务器,获取该域名的 名称服务器(域名注册商的服务器)。
- 本地域名服务器向 名称服务器 请求 域名-IP 映射。
- 缓存解析结果
PS:计算机网络(谢希仁) 258页。
- Local DNS 劫持:由于 HttpDns 是通过 IP 直接请求 HTTP 获取服务器 A 记录地址,不存在向本地运营商询问domain 解析过程,所以从根本避免了劫持问题。
- 平均访问延迟下降:由于是 IP 直接访问省掉了一次 domain 解析过程,通过智能算法排序后找到最快节点进行访问。
- 用户连接失败率下降:通过算法降低以往失败率过高的服务器排序,通过时间近期访问过的数据提高服务器排序,通过历史访问成功记录提高服务器排序。
17.http数据压缩
Accept-Encoding 和Content-Encoding是HTTP中用来对采用哪种编码格式传输正文进行协定的一对头部字段。
工作原理如下:
- 客户端发送请求时,通过Accept-Encoding带上自己支持的内容编码格式列表;
- 服务端在接收到请求后,从中挑选出一种用来对响应信息进行编码,并通过Content-Encoding来说明服务端选定的编码信息。
客户端在拿到响应正文后,依据Content-Encoding进行解压。
服务端也可以返回未压缩的正文,但这种情况不允许返回Content-Encoding
数据结构+算法
考察这部分知识,主要是手写代码,一般情况下只考数组、链表、二叉树。一般算法都来自剑指offer和leetcode。
基本数据结构
1. 二分查找的时间复杂度?手写二分查找?
二分查找的时间复杂度:O(logn)
二分查找算法:
int binarySearch(int[] arr, int key){
int low = 0;
int high = arr.length-1;
int mid = 0;
while(low<=high){
mid = (low+high)/2;
if(arr[mid] == key){
return mid;
}else if(arr[mid] < key){
high = mid - 1;
}else{
low = mid + 1;
}
}
return -1;
}
2. 二叉排序树(查找树)和平衡二叉树的定义?
- 二叉排序树(查找树、搜索树):或者是一颗空树;或者是具有下列性质的二叉树:(1)若它的左子树不空,则左子树结点的值均小于它的根结点;(2)若它的右子树不空,则右子树结点的值均大于它的根结点;(3)它的左、右子树也分别为二叉排序树。
- 平衡二叉树:平衡二叉树又称AVL树。它或者是一颗空树,或者具有下列性质的二叉树:它的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值不超过1。若将二叉树上结点的平衡因子BF(Balance Factor)定义为该结点的左子树的深度减去它的右子树的深度则平衡二叉树上的所有结点的平衡因子只可能是-1、0、1。只要二叉树上有一个结点的平衡因子的绝对值大于1,则该二叉树就是不平衡的。
- 满二叉树:一棵深度为 k 且有 2的k次方-1 个结点的二叉树称为满二叉树。
- 完全二叉树:一棵深度为 k,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从 1 至 n 的结点一一对应时,称之为完全二叉树。
- 红黑树:1.节点是红色或黑色;2. 根节点是黑色;3.所有叶子都是黑色;4. 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点);5.从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
输入一棵二叉树,判断该二叉树是否是平衡二叉树?
public boolean IsBalanced_Solution(TreeNode root) {
if(root==null) return true;
int left = treeDepth(root.left);
int right = treeDepth(root.right);
if(Math.abs(left-right)<=1){
return IsBalanced_Solution(root.left)&&IsBalanced_Solution(root.right);
}
return false;
}
private int treeDepth(TreeNode node){
if(node==null) return 0;
int left = treeDepth(node.left);
int right = treeDepth(node.right);
return left>right?left+1:right+1;
}
3. 排序算法的时间复杂度?
| 排序算法 | 平均时间 | 最坏情况 | 辅助存储 |
|---|---|---|---|
| 简单排序 | O(n²) | O(n²) | O(1) |
| 快速排序 | O(nlogn) | O(n²) | O(logn) |
| 堆排序 | O(nlogn) | O(nlogn) | O(1) |
| 归并排序 | O(nlogn) | O(nlogn) | O(n) |
| 基数排序 | O(d(n+rd))) | O(d(n+rd))) | O(rd) |
4. 手写快速排序?
快速排序介绍:
快速排序是对起泡排序的一种改进。它的基本思想是,通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分的关键字小,则可分别对这两部分记录进行排序,以达到整个序列有序。
一趟快速排序的具体做法是:附设两个指针low 和 high,它们的初始值分别为low 和 high,设枢轴记录的关键字为 pivotKey,则先从high所指位置向前搜索找到第一个关键字小于 pivotKey 的记录和枢轴记录互相交换,然后从 low所指位置向后搜索,找到第一个关键字大于 pivotKey 的记录和枢轴记录进行交换,重复这两步直至low = high为止。
void quickSort(int[] arr, int low, int high){
if(low < high){
int pivotLoc = partition(arr,low,high);
quickSort(arr, pivotLoc+1, high);
quickSort(arr, low, pivotLoc-1);
}
}
int partition(int[] arr, int low, int high){
int pivotKey = arr[low];
while(low < high){
while(low < high && arr[high] >= pivotKey){
high --;
}
arr[low] = arr[high];
while(low < high && arr[low] <= pivotKey){
low ++;
}
arr[high] = arr[low];
}
a[low] = pivotKey;
return low;
}
通常,快速排序被认为是,在所有同数量级(O(nlogn))的排序算法中,其平均性能最好。但是,若初始记录序列按关键字有序或者基本有序时,快速排序将蜕化为起泡排序,其时间复杂度为O(n²)。
快速排序优化:在指针 high 减1 和 low 增1的同时进行“起泡“操作,即相邻两个记录处于“逆序“时进行交换,同时在算法中附设两个布尔型变量分别指示指针 low和 high在两端向中间移动的过程中是否进行交换记录的操作,若指针 low从低端向中间移动过程中没有进行记录交换的操作,则不再对低端子表进行排序;类似地,若指针 high在从高端向中间移动过程中没有进行交换记录的操作,则不再需要对高端子表进行排序。显然,如此“划分“将进一步改善跨素排序的性能。
5.如何从100万个数中找出最大的前100个数?
- 取前m个元素(例如m=100),建立一个小顶堆。保持一个小顶堆得性质的步骤,运行时间为O(lgm);建立一个小顶堆运行时间为m*O(lgm)=O(m lgm);
- 顺序读取后续元素,直到结束。每次读取一个元素,如果该元素比堆顶元素小,直接丢弃
如果大于堆顶元素,则用该元素替换堆顶元素,然后保持最小堆性质。最坏情况是每次都需要替换掉堆顶的最小元素,因此需要维护堆的代价为(N-m)*O(lgm); 最后这个堆中的元素就是前最大的10W个。时间复杂度为O(N lgm)。
5. 大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项(从0开始,第0项为0)。
非递归:
public int Fibonacci(int n) {
if(n==0) return 0;
if(n==1) return 1;
int a = 0;
int b = 1;
int c = 0;
for(int i=2;i<=n;i++){
c = a + b;
a = b;
b = c;
}
return c;
}
递归:
public int Fibonacci(int n) {
if(n==0) return 0;
if(n==1) return 1;
return Fibonacci(n-1)+Fibonacci(n-2);
}
数组
6. 一只青蛙一次可以跳上1级台阶,也可以跳上2级……它也可以跳上n级。求该青蛙跳上一个n级的台阶总共有多少种跳法。
public int JumpFloorII(int target) {
int sum =1;
for(int i=1;i<target;i++){
sum +=JumpFloorII(i);
}
return sum;
}
7. 输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位置不变。
冒泡排序算法思想:
public void reOrderArray(int [] array) {
}
8. 定义栈的数据结构,请在该类型中实现一个能够得到栈中所含最小元素的min函数(时间复杂度应为O(1))。
public class Solution {
int[] arr = new int[128];
int top = -1;
int m;
public void push(int node) {
top++;
arr[top] = node;
resetMin();
}
public void pop() {
top--;
resetMin();
}
//重置最小元素
private void resetMin(){
int min = Integer.MAX_VALUE;
for(int i=0;i<=top;i++){
if(min>arr[i]){
min = arr[i];
}
}
m = min;
}
public int top() {
if(top>=0) return arr[top];
return -1;
}
public int min() {
return m;
}
}
9. 数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。例如输入一个长度为9的数组{1,2,3,2,2,2,5,4,2}。由于数字2在数组中出现了5次,超过数组长度的一半,因此输出2。如果不存在则输出0。
思路:用一个计数器来记录前一个数的次数,如果当前数字与前一个数字相等,就加1,不相等就减1,如果一个数字超过数组长度的一半,那么最后计数器会大于0。
public int MoreThanHalfNum_Solution(int [] array) {
if(array==null) return 0;
int counter = 1;
int num = array[0];
for(int i=1;i<array.length;i++){
if(num==array[i]){
counter++;
}else if(counter==0){
if(i<array.length-1){
counter = 1;
num = array[i];
}
}else{
counter--;
}
}
if(counter>0) return num;
return 0;
}
10. 输入n个整数,找出其中最小的K个数。例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4。 11. 统计一个数字在排序数组中出现的次数。 12. 一个整型数组里除了两个数字之外,其他的数字都出现了偶数次。请写程序找出这两个只出现一次的数字。 13. 给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成。 14. 给定一个数组 nums 和一个值 val,你需要原地移除所有数值等于 val 的元素,返回移除后数组的新长度。不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成。元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。 15. 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。你可以假设数组中无重复元素。 16. 给定一个 m x n 的矩阵,如果一个元素为 0,则将其所在行和列的所有元素都设为 0。请使用原地算法。 17. 定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。 18. 给定一个整数数组 a,其中1 ≤ a[i] ≤ n (n为数组长度), 其中有些元素出现两次而其他元素出现一次。找到所有出现两次的元素。 19. 在MATLAB中,有一个非常有用的函数 reshape,它可以将一个矩阵重塑为另一个大小不同的新矩阵,但保留其原始数据。给出一个由二维数组表示的矩阵,以及两个正整数r和c,分别表示想要的重构的矩阵的行数和列数。重构后的矩阵需要将原始矩阵的所有元素以相同的行遍历顺序填充。如果具有给定参数的reshape操作是可行且合理的,则输出新的重塑矩阵;否则,输出原始矩阵。 20. 给定一个包含 n + 1 个整数的数组 nums,其数字都在 1 到 n 之间(包括 1 和 n),可知至少存在一个重复的整数。假设只有一个重复的整数,找出这个重复的数。
链表
21. 输入一个链表,按链表值从尾到头的顺序返回一个ArrayList。 22. 输入一个链表,输出该链表中倒数第k个结点。 23. 输入一个链表,反转链表后,输出新链表的表头。 24. 输入两个单调递增的链表,输出两个链表合成后的链表,当然我们需要合成后的链表满足单调不减规则。 25. 给一个链表,若其中包含环,请找出该链表的环的入口结点,否则,输出null。
二叉树
26. 输入两棵二叉树A,B,判断B是不是A的子结构。(ps:我们约定空树不是任意一个树的子结构)。 27. 操作给定的二叉树,将其变换为源二叉树的镜像。 28. 输入一颗二叉树的跟节点和一个整数,打印出二叉树中结点值的和为输入整数的所有路径。路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径。(注意: 在返回值的list中,数组长度大的数组靠前)。 29. 输入一棵二叉树,求该树的深度。从根结点到叶结点依次经过的结点(含根、叶结点)形成树的一条路径,最长路径的长度为树的深度。 30. 输入一棵二叉树,判断该二叉树是否是平衡二叉树。 31. 请实现一个函数,用来判断一颗二叉树是不是对称的。注意,如果一个二叉树同此二叉树的镜像是同样的,定义其为对称的。 32. 请实现一个函数按照之字形打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右至左的顺序打印,第三行按照从左到右的顺序打印,其他行以此类推。 33. 从上到下按层打印二叉树,同一层结点从左至右输出。每一层输出一行。 34. 给定一棵二叉搜索树,请找出其中的第k小的结点。例如, (5,3,7,2,4,6,8) 中,按结点数值大小顺序第三小结点的值为4。
数据库
考察数据库知识时,考的比较少,最多也是问一下sql语句。
1.数据库升级会调用哪些方法? 2.基本的增删该查语句?
计算机操作系统
考察计算机操作系统知识时,也考的比较少。
1.进程之间如何通行? 2.线程与进程之间的区别?
Android开源库
考察Android开源库时,必须要知道熟悉的开源库的原理。比如:
1.EventBus 的原理?
为什么会选择使用EventBus来做通信?
- 简化了组件间交流的方式
- 对事件通信双方进行解耦
- 可以灵活方便的指定工作线程,通过 ThreadMode 速度快,
- 性能好
- 库比较小,不占内存
- 有权威性
- 功能多,使用方便
订阅:
- 根据反射,找到所有含有Subscribe注解的方法,将方法封装放到一个 ArrayList 集合里面去,再以注册对象的类为 key ,方法集合为 value 放到一个 ConcurrentHashMap 中。
- 遍历方法集合,根据参数类型分类。将订阅对象和订阅方法封装到一个对象中,然后把这个对象根据方法Subscribe注解的优先级添加到一个 CopyOnWriteArrayList 中,最后以参数类型为 key,CopyOnWriteArrayList 为 value 放到一个HashMap中。在每一个方法订阅中,还会去检查一下方法是否是粘性的,如果是就会检查是否存在相同参数类型的发布的粘性事件,如果有会执行此方法。
发布:
- 先将事件放到一个队列中,然后遍历队列,根据事件类型找到方法。
- 据方法的注解ThreadMode(POSTING,MAIN,MIAN_ORDERED ,BACKGROUND,ASYNC)决定在哪一个线程里面执行订阅方法,通过反射执行方法。
ThreadMode 执行的方式:
- POSTING:在当前线程中,立即执行。
- MAIN:如果当前线程是主线程,就立即执行;否则,放到主线程消息队列中执行。
- MIAN_ORDERED:放到主线程消息队列中执行。
- BACKGROUND:如果当前线程是子线程,就立即执行;否则,放到子线程消息队列,串行执行。
- ASYNC:放到子线程消息队列,并发执行。
使用EventBus发送一个消息与使用Handler发送一个消息的区别: 根据情况而定。
- EventBus:发送的消息会马上执行。
- Handler:发送的消息是异步执行的。
普通事件和粘性事件的区别:
- 普通事件:必须先订阅,才能发送执行。
- 粘性事件:先发送等待订阅了才执行。
粘性事件:
- 发布:先将粘性事件存储起来,key为事件类型,value为事件对象。然后检测当前之前是否有订阅过该粘性事件,如果有就执行。
- 订阅:订阅完成后,会检测订阅的事件中是否有粘性事件,如果有,再检测之间是否有发布过粘性事件,如果有就立即执行订阅的粘性事件。
2.Glide 的性能、优势和缓存原理?
性能:Glide 充分考虑了Android图片加载性能的两个关键方面。
- 图片解码速度
- 解码图片带来的资源压力
优势:Glide使用了多个步骤来确保在Android上加载图片尽可能的快速和平滑。
- 自动、智能地下采样(downsampling)和缓存(caching),以最小化存储开销和解码次数;
- 积极的资源重用,例如字节数组和Bitmap,以最小化昂贵的垃圾回收和堆碎片影响;
- 深度的生命周期集成,以确保仅优先处理活跃的Fragment和Activity的请求,并有利于应用在必要时释放资源以避免在后台时被杀掉。
缓存原理:默认情况下,Glide 会在开始一个新的图片请求之前检查以下多级的缓存。
活动资源 (Active Resources) : 现在是否有另一个 View 正在展示这张图片?
内存缓存 (Memory cache) : 该图片是否最近被加载过并仍存在于内存中?
资源类型(Resource):该图片是否之前曾被解码、转换并写入过磁盘缓存?
数据来源 (Data) : 构建这个图片的资源是否之前曾被写入过文件缓存?
Glid 中 LruCache 的 key 是怎样生成的:
3.LeakCanary的原理?
- 在Application中注册Activity生命周期方法回调的监听器。
- 监听Activity/Fragment的onDestroy方法。
- 在onDestroy方法中,将类对象包装成弱引用添加到引用队列中。
- 检测弱引用有没有被回收,如果回收了就没有内存泄漏;如果没有回收,就手动GC,手动GC后还没有回收,就怀疑是内存泄漏。
- 获取内存快照,通过 可达性分析算法,找出泄漏的对象。
Kotlin
1.扩展函数与普通函数的区别?
定义的扩展函数,会放在生成的一个以(类名+kt结尾)的扩展类中,扩展方法就是这个类里面的静态方法。
2.内联函数?
函数体会被直接替换到函数被调用的地方。
3.闭包?
- 函数里面声明函数,函数里面返回函数,就是闭包。
- 闭包就是一个代码块,用“{ }”包起来。
4.协程?
- 是一种比线程更加轻量级的存在。
- 正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。
参考书籍
- Android开发艺术探索
- 深入Java虚拟机
- Java并发编程实践
- Head First设计模式
- Effective Java(中文版第二版)
- 重构(改善代码既有代码的设计)
- 数据结构(严蔚敏)
- 程序员代码面试指南
- [计算机网络第五版]计算机网络第五版
- Kotlin
背调问题
- 工作时间
- 职位
- 同事关系
- 工作态度
- 职业操守:有没有与公司发生过纠纷
- 离职原因
- 做了哪些事情
- 做的事情是否是自己主导的
- 评价:10分打分,有哪些要提高的
- 有没有竞业协议,劳动纠纷等
文档信息
- 本文作者:Wang Jiang
- 本文链接:https://wjrye.github.io/wiki/2020-12-06-Android-Interview/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)